Capítulo 4 Tidyverse y Tasas básicas del Mercado de Trabajo
Reiniciar R
4.1 Estructuración de Bases de Datos
A lo largo de esta clase, trabajaremos con el paquete Tidyverse. El mismo agrupa una serie de paquetes que tienen una misma lógica en su diseño y por ende funcionan en armonía.
Entre ellos usaremos principalmente dplyr y tidyr para realizar transformaciones sobre nuestro set de datos, y ggplot para realizar gráficos (éste último se verá en la clase 3).
A continuación cargamos la librería a nuestro ambiente. Para ello debe estar previamente instalada en nuestra pc.
library(tidyverse)Para mostrar el funcionamiento básico de tydyverse, crearemos un pequeño set de datos del Indice de salarios.
INDICE <- c(100, 100, 100,
101.8, 101.2, 100.73,
102.9, 102.4, 103.2)
FECHA <- c("Oct-16", "Oct-16", "Oct-16",
"Nov-16", "Nov-16", "Nov-16",
"Dic-16", "Dic-16", "Dic-16")
GRUPO <- c("Privado_Registrado","Público","Privado_No_Registrado",
"Privado_Registrado","Público","Privado_No_Registrado",
"Privado_Registrado","Público","Privado_No_Registrado")
Datos <- data.frame(INDICE, FECHA, GRUPO)4.2 Dplyr
El caracter principal para utilizar este paquete es %>% , pipe (de tubería).
Los %>% toman el set de datos a su izquierda, y los transforman mediante los comandos a su derecha, en los cuales los elementos de la izquierda están implícitos. Es decír, que una vez específicado el DataFrame con el cual se trabaja, no será necesario nombrarlo nuevamente para referirse a una determinada variable/columna del mismo.
Veamos las principales funciones que pueden utilizarse con la lógica de este paquete:
4.2.1 filter
Permite filtrar la tabla acorde al cumplimiento de condiciones lógicas
Datos %>%
filter(INDICE>101 , GRUPO == "Privado_Registrado")## INDICE FECHA GRUPO
## 1 101.8 Nov-16 Privado_Registrado
## 2 102.9 Dic-16 Privado_RegistradoNótese que en este caso al separar con una , las condiciones se exige el cumplimiento de ambas. En caso de desear que se cumpla una sola condición debe utilizarse el caracter |
Datos %>%
filter(INDICE>101 | GRUPO == "Privado_Registrado")## INDICE FECHA GRUPO
## 1 100.0 Oct-16 Privado_Registrado
## 2 101.8 Nov-16 Privado_Registrado
## 3 101.2 Nov-16 Público
## 4 102.9 Dic-16 Privado_Registrado
## 5 102.4 Dic-16 Público
## 6 103.2 Dic-16 Privado_No_Registrado4.2.2 rename
Permite renombrar una columna de la tabla. Funciona de la siguiente manera:
Data %>% rename( nuevo_nombre = viejo_nombre )
Datos %>%
rename(Periodo = FECHA)## INDICE Periodo GRUPO
## 1 100.00 Oct-16 Privado_Registrado
## 2 100.00 Oct-16 Público
## 3 100.00 Oct-16 Privado_No_Registrado
## 4 101.80 Nov-16 Privado_Registrado
## 5 101.20 Nov-16 Público
## 6 100.73 Nov-16 Privado_No_Registrado
## 7 102.90 Dic-16 Privado_Registrado
## 8 102.40 Dic-16 Público
## 9 103.20 Dic-16 Privado_No_RegistradoNótese que a diferencia del ejemplo de la función filter donde utilizábamos == para comprobar una condición lógica, en este caso se utiliza sólo un = ya que lo estamos haciendo es asignar un nombre.
4.2.3 mutate
Permite agregar una variable a la tabla (especificando el nombre que tomará esta), que puede ser el resultado de operaciones sobre otras variables de la misma tabla.
En caso de especificar el nombre de una columna existente, el resultado de la operación realizada “sobrescribirá” la información de la columna con dicho nombre
Datos <- Datos %>%
mutate(Doble=INDICE*2)
Datos## INDICE FECHA GRUPO Doble
## 1 100.00 Oct-16 Privado_Registrado 200.00
## 2 100.00 Oct-16 Público 200.00
## 3 100.00 Oct-16 Privado_No_Registrado 200.00
## 4 101.80 Nov-16 Privado_Registrado 203.60
## 5 101.20 Nov-16 Público 202.40
## 6 100.73 Nov-16 Privado_No_Registrado 201.46
## 7 102.90 Dic-16 Privado_Registrado 205.80
## 8 102.40 Dic-16 Público 204.80
## 9 103.20 Dic-16 Privado_No_Registrado 206.404.2.4 case_when
Permite definir una variable, la cual toma un valor particular para cada condición establecida. En caso de no cumplir ninguna de las condiciones establecidas la variable tomara valor NA.
Su funcionamiento es el siguiente:
case_when(condicion1 ~ "Valor1",condicion2 ~ "Valor2",condicion3 ~ "Valor3")
Datos <- Datos %>%
mutate(Caso_cuando = case_when(GRUPO == "Privado_Registrado" ~ INDICE*2,
GRUPO == "Público" ~ INDICE*3,
GRUPO == "Privado_No_Registrado"~ INDICE*5))
Datos## INDICE FECHA GRUPO Doble Caso_cuando
## 1 100.00 Oct-16 Privado_Registrado 200.00 200.00
## 2 100.00 Oct-16 Público 200.00 300.00
## 3 100.00 Oct-16 Privado_No_Registrado 200.00 500.00
## 4 101.80 Nov-16 Privado_Registrado 203.60 203.60
## 5 101.20 Nov-16 Público 202.40 303.60
## 6 100.73 Nov-16 Privado_No_Registrado 201.46 503.65
## 7 102.90 Dic-16 Privado_Registrado 205.80 205.80
## 8 102.40 Dic-16 Público 204.80 307.20
## 9 103.20 Dic-16 Privado_No_Registrado 206.40 516.004.2.5 select
Permite especificar la serie de columnas que se desea conservar de un DataFrame. También pueden especificarse las columnas que se desean descartar (agregándoles un -). Muy útil para agilizar el trabajo en bases de datos de gran tamaño.
Datos2 <- Datos %>%
select(INDICE, FECHA, GRUPO)
Datos2## INDICE FECHA GRUPO
## 1 100.00 Oct-16 Privado_Registrado
## 2 100.00 Oct-16 Público
## 3 100.00 Oct-16 Privado_No_Registrado
## 4 101.80 Nov-16 Privado_Registrado
## 5 101.20 Nov-16 Público
## 6 100.73 Nov-16 Privado_No_Registrado
## 7 102.90 Dic-16 Privado_Registrado
## 8 102.40 Dic-16 Público
## 9 103.20 Dic-16 Privado_No_RegistradoDatos <- Datos %>%
select(-c(Doble,Caso_cuando))
Datos## INDICE FECHA GRUPO
## 1 100.00 Oct-16 Privado_Registrado
## 2 100.00 Oct-16 Público
## 3 100.00 Oct-16 Privado_No_Registrado
## 4 101.80 Nov-16 Privado_Registrado
## 5 101.20 Nov-16 Público
## 6 100.73 Nov-16 Privado_No_Registrado
## 7 102.90 Dic-16 Privado_Registrado
## 8 102.40 Dic-16 Público
## 9 103.20 Dic-16 Privado_No_Registrado4.2.6 arrange
Permite ordenar la tabla por los valores de determinada/s variable/s. Es útil cuando luego deben hacerse otras operaciones que requieran del ordenamiento de la tabla
Datos <- Datos %>%
arrange(GRUPO, INDICE)
Datos## INDICE FECHA GRUPO
## 1 100.00 Oct-16 Privado_No_Registrado
## 2 100.73 Nov-16 Privado_No_Registrado
## 3 103.20 Dic-16 Privado_No_Registrado
## 4 100.00 Oct-16 Privado_Registrado
## 5 101.80 Nov-16 Privado_Registrado
## 6 102.90 Dic-16 Privado_Registrado
## 7 100.00 Oct-16 Público
## 8 101.20 Nov-16 Público
## 9 102.40 Dic-16 Público4.2.7 summarise
Crea una nueva tabla que resume la información original. Para ello, definimos las variables de resumen y las formas de agregación.
Datos %>%
summarise(Indprom = mean(INDICE))## Indprom
## 1 101.35894.2.8 group_by
Esta función permite realizar operaciones de forma agrupada. Lo que hace la función es “separar” a la tabla según los valores de la variable indicada y realizar las operaciones que se especifican a continuación, de manera independiente para cada una de las “subtablas”. En nuestro ejemplo, sería útil para calcular el promedio de los indices por Fecha
Datos %>%
group_by(FECHA) %>%
summarise(Indprom = mean(INDICE))## # A tibble: 3 x 2
## FECHA Indprom
## <fct> <dbl>
## 1 Dic-16 103.
## 2 Nov-16 101.
## 3 Oct-16 100Notese que los %>% pueden usarse encadenados para realizar numerosos procedimientos sobre un dataframe original.
Veamos un ejemplo con multiples encadenamietnos
Encadenado <- Datos %>%
filter(GRUPO == "Privado_Registrado") %>%
rename(Periodo = FECHA) %>%
mutate(Doble = INDICE*2) %>%
select(-INDICE)4.3 Joins
Otra implementación muy importante del paquete dplyr son las funciones para unir tablas (joins)

4.3.1 left_join
Veamos un ejemplo de la función left_join (una de las más utilizadas en la práctica).
Para ello crearemos previamente un Dataframe que contenga un Ponderador para cada uno de los Grupos del Dataframe Datos. Aprovecharemos el ejemplo para introducir la función weigthed.mean, y así calcular un Indice Ponderado.
Ponderadores <- data.frame(GRUPO = c("Privado_Registrado","Público","Privado_No_Registrado"),
PONDERADOR = c(50.16,29.91,19.93))
Ponderadores## GRUPO PONDERADOR
## 1 Privado_Registrado 50.16
## 2 Público 29.91
## 3 Privado_No_Registrado 19.93Datos_join <- Datos %>%
left_join(.,Ponderadores, by = "GRUPO")
Datos_join## INDICE FECHA GRUPO PONDERADOR
## 1 100.00 Oct-16 Privado_No_Registrado 19.93
## 2 100.73 Nov-16 Privado_No_Registrado 19.93
## 3 103.20 Dic-16 Privado_No_Registrado 19.93
## 4 100.00 Oct-16 Privado_Registrado 50.16
## 5 101.80 Nov-16 Privado_Registrado 50.16
## 6 102.90 Dic-16 Privado_Registrado 50.16
## 7 100.00 Oct-16 Público 29.91
## 8 101.20 Nov-16 Público 29.91
## 9 102.40 Dic-16 Público 29.91Datos_Indice_Gral <- Datos_join %>%
group_by(FECHA) %>%
summarise(Indice_Gral = weighted.mean(INDICE,w = PONDERADOR))
Datos_Indice_Gral## # A tibble: 3 x 2
## FECHA Indice_Gral
## <fct> <dbl>
## 1 Dic-16 103.
## 2 Nov-16 101.
## 3 Oct-16 1004.4 Tidyr
El paquete tidyr esta pensado para facilitar el emprolijamiento de los datos.
Gather es una función que nos permite pasar los datos de forma horizontal a una forma vertical.
spread es una función que nos permite pasar los datos de forma vertical a una forma horizontal.
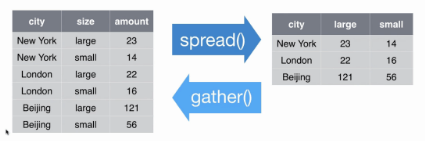
Retomemos el Dataframe original para mostrar como operan estas funciones:
Datos## INDICE FECHA GRUPO
## 1 100.00 Oct-16 Privado_No_Registrado
## 2 100.73 Nov-16 Privado_No_Registrado
## 3 103.20 Dic-16 Privado_No_Registrado
## 4 100.00 Oct-16 Privado_Registrado
## 5 101.80 Nov-16 Privado_Registrado
## 6 102.90 Dic-16 Privado_Registrado
## 7 100.00 Oct-16 Público
## 8 101.20 Nov-16 Público
## 9 102.40 Dic-16 Público4.4.1 Gather y Spread
Datos_Spread <- Datos %>%
spread(., # el . llama a lo que esta atras del %>%
key = GRUPO, #la llave es la variable cuyos valores van a dar los nombres de columnas
value = INDICE) #los valores con que se llenan las celdas
Datos_Spread ## FECHA Privado_No_Registrado Privado_Registrado Público
## 1 Dic-16 103.20 102.9 102.4
## 2 Nov-16 100.73 101.8 101.2
## 3 Oct-16 100.00 100.0 100.0##La función opuesta (gather) nos permite obtener un dataframe como el original partiendo de un dataframe como el recién construido.
Datos_gather <- Datos_Spread %>%
gather(., # el . llama a lo que esta atras del %>%
key = GRUPO, # como se llamará la variable que toma los nombres de las columnas
value = INDICE, # como se llamará la variable que toma los valores de las columnas
2:4) #le indico que columnas juntar
Datos_gather## FECHA GRUPO INDICE
## 1 Dic-16 Privado_No_Registrado 103.20
## 2 Nov-16 Privado_No_Registrado 100.73
## 3 Oct-16 Privado_No_Registrado 100.00
## 4 Dic-16 Privado_Registrado 102.90
## 5 Nov-16 Privado_Registrado 101.80
## 6 Oct-16 Privado_Registrado 100.00
## 7 Dic-16 Público 102.40
## 8 Nov-16 Público 101.20
## 9 Oct-16 Público 100.004.5 Tasas del Mercado de Trabajo
Luego de abordar las principales funciones necesarias para operar sobre las bases de datos, trabajaremos a continuación con la base del 1er Trimestre de 2017 de la EPH. El ejercicio principal consistirá en calcular la tasa de empleo, definida como:
- Tasa de empleo: \(\frac{Ocupados}{Población}\)
Una vez alcanzado dicho resultado, se extenderá el ejercicio hacia el conjunto de tasas básicas presentadas en los Cuadros 1.1 y 1.2, del Informe técnico elaborado por EPH-INDEC. Por último se realizará una modificación para calcular al mismo tiempo las tasas básicas de 2 trimestres consecutivos.
En la carpeta de FUENTES del curso, se encuentra el archivo “EPH_Registro” que contiene las codificación de cada una de las variables de la base, y el archivo “EPH_Concpetos_Actividad” que contiene las definiciones de los Estados ocupacionales a partir de los cuales se construyen las tasas básicas.
Cargamos la librería que usaremos para leer y escribir archivos en excel.
library(openxlsx) Carga de Informacion
La función list.files nos permite observar los archivos que contiene una determinada carpeta
list.files("../Fuentes/")## character(0)La función read.table nos permite levantar los archivos de extensión “.txt”
La función read.xlsx nos permite levantar los archivos de extensión “.xlsx”
Levantamos la base individual del primer trimestre de 2017, y un listado que contiene los Nombres y Códigos de los Aglomerados EPH.
Individual_t117 <-
read.table("Fuentes/usu_individual_t117.txt",
sep = ";",
dec = ",",
header = TRUE,
fill = TRUE )
Aglom <- read.xlsx("Fuentes/Aglomerados EPH.xlsx")4.5.1 Tasa de Empleo
Creamos una tabla con los niveles de:
- Población
- Ocupados
Estos niveles nos van a permitir calcular la tasa de forma sencilla.
- Población: Si contaramos cuantos registros tiene la base, simplemente tendríamos el numero de individuos muestral de la EPH, por ende debemos sumar los valores de la variable PONDERA, para contemplar a cuantas personas representa cada individuo encuestado.
- Ocupados: En este caso, debemos agregar un filtro al procedimiento anterior, ya que unicamente queremos sumar los ponderadores de aquellas personas que se encuentran ocupadas. (La lógica seria: “Suma los valores de la columna PONDERA, solo para aquellos registros donde el ESTADO == 1”)
Poblacion_ocupados <- Individual_t117 %>%
summarise(Poblacion = sum(PONDERA),
Ocupados = sum(PONDERA[ESTADO == 1]))
Poblacion_ocupados## Poblacion Ocupados
## 1 27416497 11328384La función summarise() nos permite crear multiples variables de resumen al mismo tiempo, simplemente separando con una , cada uno de ellas. A su vez, se pueden crear variables, a partir de las variables creadas por la propia función. De esta forma, podemos, directamente calcular la tasa de empleo a partir del total poblacional y de ocupados.
Empleo <- Individual_t117 %>%
summarise(Poblacion = sum(PONDERA),
Ocupados = sum(PONDERA[ESTADO == 1]),
Tasa_Empleo = Ocupados/Poblacion)
Empleo## Poblacion Ocupados Tasa_Empleo
## 1 27416497 11328384 0.4131959Una vez calculada la tasa, incluso podríamos desechar las variables de nivel, para conservar unicamente la tasas
Empleo %>%
select(-(1:2))## Tasa_Empleo
## 1 0.41319594.5.2 Tásas Básicas - Total Aglomerados
Con la misma lógica del ejemplo anterior, podemos construir con solo una porción de código adicional el Cuadro 1.1 del Informe técnico de Mercado de trabajo EPH-INDEC.
####Cuadro 1.1 Principales indicadores. Total 31 aglomerados u
Cuadro_1.1a <- Individual_t117 %>%
summarise(Poblacion = sum(PONDERA),
Ocupados = sum(PONDERA[ESTADO == 1]),
Desocupados = sum(PONDERA[ESTADO == 2]),
PEA = Ocupados + Desocupados,
Ocupados_demand = sum(PONDERA[ESTADO == 1 & PP03J ==1]),
Suboc_demandante = sum(PONDERA[ESTADO == 1 & INTENSI ==1 & PP03J==1]),
Suboc_no_demand = sum(PONDERA[ESTADO == 1 & INTENSI ==1 & PP03J %in% c(2,9)]),
Subocupados = Suboc_demandante + Suboc_no_demand ,
# También podemos llamar a las variables entre comillas, incluyendo nombres compuestos
# A su vez, podemos utilizar la variable recién creada en la definción de otra varible
'Tasa Actividad' = PEA/Poblacion,
'Tasa Empleo' = Ocupados/Poblacion,
'Tasa Desocupacion' = Desocupados/PEA,
'Tasa ocupados demandantes' = Ocupados_demand/PEA,
'Tasa Subocupación' = Subocupados/PEA,
'Tasa Subocupación demandante' = Suboc_demandante/PEA,
'Tasa Subocupación no demandante' = Suboc_no_demand/PEA)
Cuadro_1.1a ## Poblacion Ocupados Desocupados PEA Ocupados_demand Suboc_demandante
## 1 27416497 11328384 1149128 12477512 1757938 829323
## Suboc_no_demand Subocupados Tasa Actividad Tasa Empleo Tasa Desocupacion
## 1 410709 1240032 0.4551096 0.4131959 0.09209592
## Tasa ocupados demandantes Tasa Subocupación Tasa Subocupación demandante
## 1 0.1408885 0.09938135 0.06646541
## Tasa Subocupación no demandante
## 1 0.03291594Una vez que calculamos las tasas, podemos borrar los niveles poblacionales con un select
Cuadro_1.1a <- Cuadro_1.1a %>%
select(-c(1:8))
Cuadro_1.1a## Tasa Actividad Tasa Empleo Tasa Desocupacion Tasa ocupados demandantes
## 1 0.4551096 0.4131959 0.09209592 0.1408885
## Tasa Subocupación Tasa Subocupación demandante
## 1 0.09938135 0.06646541
## Tasa Subocupación no demandante
## 1 0.03291594Con gather podemos dar vuelta la tabla para que quede como en la publicación
Cuadro_1.1a <- Cuadro_1.1a %>%
gather(Tasas, Valor, 1:ncol(.))
Cuadro_1.1a## Tasas Valor
## 1 Tasa Actividad 0.45510964
## 2 Tasa Empleo 0.41319589
## 3 Tasa Desocupacion 0.09209592
## 4 Tasa ocupados demandantes 0.14088850
## 5 Tasa Subocupación 0.09938135
## 6 Tasa Subocupación demandante 0.06646541
## 7 Tasa Subocupación no demandante 0.03291594En caso de querer expresar los resultados como porcentajes, utilizamos la función sprintf. Para ello debemos utilizar mutate para transformar la columna Valor.
Cuadro_1.1a <- Cuadro_1.1a %>%
mutate(Valor = sprintf("%1.1f%%", 100*Valor))
Cuadro_1.1a## Tasas Valor
## 1 Tasa Actividad 45.5%
## 2 Tasa Empleo 41.3%
## 3 Tasa Desocupacion 9.2%
## 4 Tasa ocupados demandantes 14.1%
## 5 Tasa Subocupación 9.9%
## 6 Tasa Subocupación demandante 6.6%
## 7 Tasa Subocupación no demandante 3.3%Nótese que en este caso, para poder añadir el %, la función transforma a la variable en un Character, por ende debe tenerse en cuenta que se pierde la información del numero completo.
4.5.3 Tásas Básicas por Aglomerado
En este caso, podemos ver que simplemente agregando la función group_by podemos replicar el procedimiento para cada uno de los aglomerados. Y a su vez, podemos realizar en un solo paso los arreglos posteriores sobre nuestra tabla.
Cuadro_1.2a <- Individual_t117 %>%
group_by(AGLOMERADO) %>%
summarise(Poblacion = sum(PONDERA),
Ocupados = sum(PONDERA[ESTADO == 1]),
Desocupados = sum(PONDERA[ESTADO == 2]),
PEA = Ocupados + Desocupados,
Ocupados_demand = sum(PONDERA[ESTADO == 1 & PP03J == 1]),
Suboc_demandante = sum(PONDERA[ESTADO == 1 & INTENSI == 1 & PP03J == 1]),
Suboc_no_demand = sum(PONDERA[ESTADO == 1 & INTENSI == 1 & PP03J %in% c(2, 9)]),
Subocupados = Suboc_demandante + Suboc_no_demand,
'Tasa Actividad' = PEA/Poblacion,
'Tasa Empleo' = Ocupados/Poblacion,
'Tasa Desocupacion' = Desocupados/PEA,
'Tasa ocupados demandantes' = Ocupados_demand/PEA,
'Tasa Subocupación' = Subocupados/PEA,
'Tasa Subocupación demandante' = Suboc_demandante/PEA,
'Tasa Subocupación no demandante' = Suboc_no_demand/PEA)
Cuadro_1.2a[1:10,]## # A tibble: 10 x 16
## AGLOMERADO Poblacion Ocupados Desocupados PEA Ocupados_demand
## <int> <int> <int> <int> <int> <int>
## 1 2 860385 359528 31209 390737 51047
## 2 3 308455 131538 10823 142361 11802
## 3 4 1293438 554680 63370 618050 90662
## 4 5 519469 206044 11279 217323 12185
## 5 6 218671 90908 4181 95089 7247
## 6 7 356298 138937 5928 144865 11973
## 7 8 383974 133077 1867 134944 7660
## 8 9 220357 82286 4639 86925 8478
## 9 10 937900 380621 18830 399451 35043
## 10 12 369673 148114 5956 154070 7086
## # … with 10 more variables: Suboc_demandante <int>, Suboc_no_demand <int>,
## # Subocupados <int>, `Tasa Actividad` <dbl>, `Tasa Empleo` <dbl>, `Tasa
## # Desocupacion` <dbl>, `Tasa ocupados demandantes` <dbl>, `Tasa
## # Subocupación` <dbl>, `Tasa Subocupación demandante` <dbl>, `Tasa
## # Subocupación no demandante` <dbl>Cuadro_1.2a <- Cuadro_1.2a %>%
select(-c(2:9)) %>% # Eliminamos las variables de nivel
left_join(.,Aglom) %>% # Agregamos el nombre de los aglomerados, que teniamos en otro DF
select(Nom_Aglo,everything(.),-AGLOMERADO) #Eliminamos el código de los aglomerados## Joining, by = "AGLOMERADO"Cuadro_1.2a[1:10,]## # A tibble: 10 x 8
## Nom_Aglo `Tasa Actividad` `Tasa Empleo` `Tasa Desocupac…
## <chr> <dbl> <dbl> <dbl>
## 1 " Gran … 0.454 0.418 0.0799
## 2 " Bahía… 0.462 0.426 0.0760
## 3 " Gran … 0.478 0.429 0.103
## 4 " Gran … 0.418 0.397 0.0519
## 5 " Gran … 0.435 0.416 0.0440
## 6 " Posad… 0.407 0.390 0.0409
## 7 " Gran … 0.351 0.347 0.0138
## 8 " Cdro.… 0.394 0.373 0.0534
## 9 " Gran … 0.426 0.406 0.0471
## 10 " Corri… 0.417 0.401 0.0387
## # … with 4 more variables: `Tasa ocupados demandantes` <dbl>, `Tasa
## # Subocupación` <dbl>, `Tasa Subocupación demandante` <dbl>, `Tasa
## # Subocupación no demandante` <dbl>4.5.4 Ejercicio para 2 trimestres
A continuación se detallaran los procedimientos necesarios para realizar apilar las bases de dos o más trimestres y calcular de manera conjunta indicadores para cada uno de ellos.
Levantamos la base del 4to Trimestre de 2016
Individual_t416 <-
read.table("Fuentes/usu_individual_t416.txt",
sep = ";",
dec = ",",
header = TRUE,
fill = TRUE ) 4.5.4.1 Select - variables de interés
Para este tipo de ejercicios, donde el volumen de datos es relativamente grande, puede resultar útil restringir la base a nuestras variables de interés para que el procesamiento no sea tan costoso. Para ello, creando previamente un vector de strings con los nombres de las variables, podemos utilizar de la siguiente manera la función select para quedarnos sólamente con las mismas.
Variables_interes <- c("ANO4","TRIMESTRE","ESTADO","PONDERA","REGION","AGLOMERADO")
Basesita_t416 <- Individual_t416 %>% select(Variables_interes)
Basesita_t117 <- Individual_t117 %>% select(Variables_interes)4.5.4.2 bind_rows
La función bind_rows nos permitirá apilar dos bases de datos en un solo dataframe. La misma evalua los nombres de las variables de cada una de las bases para adjuntar el contenido de ambas en las variables comunes. En caso de que una de las bases tuviera una variable que la otra no, se conservaran dichos datos, quedando como NA los valores para la otra base.
Union_Bases <- bind_rows(Basesita_t416,Basesita_t117)
##alternativamente
Union_Bases <- Basesita_t416 %>%
bind_rows(Basesita_t117)Una vez que contamos con nuestra unión de las bases de 2 o más trimestres, procederemos a realizar los cálculos que deseamos agrupando por las variables ANO4 y TRIMESTRE. Esto nos permitirá realizar estimaciones para sendos períodos al mismo tiempo. Por ejemplo, a continuación tomamos parte del código desarrollado anteriormente para calcular las tasas de Actividad, Empleo, y Desocupación.
Tasas_dos_trimestres <- Union_Bases %>%
group_by(ANO4,TRIMESTRE) %>%
summarise(Poblacion = sum(PONDERA),
Ocupados = sum(PONDERA[ESTADO == 1]),
Desocupados = sum(PONDERA[ESTADO == 2]),
PEA = Ocupados + Desocupados,
'Tasa Actividad' = PEA/Poblacion,
'Tasa Empleo' = Ocupados/Poblacion,
'Tasa Desocupacion' = Desocupados/PEA) %>%
select(1:2,7:ncol(.))
Tasas_dos_trimestres## # A tibble: 2 x 5
## # Groups: ANO4 [2]
## ANO4 TRIMESTRE `Tasa Actividad` `Tasa Empleo` `Tasa Desocupacion`
## <int> <int> <dbl> <dbl> <dbl>
## 1 2016 4 0.453 0.419 0.0756
## 2 2017 1 0.455 0.413 0.09214.5.4.3 Exportar resultados a Excel
Como vieramos en la clase 1, la función write.xlsx de la libreria openxlsx nos permite exportar los dos dataframes a un mismo archivo. Cabe aclarar que existen numerosas funciones y librerías alternativas para exportar resultados a un excel. En este caso, optamos por openxlsx ya que resulta una de las más sencillas para exportar rapidamente los resultados. Otras librerías permiten también dar formato a las tablas que se exportan, definir si deseamos sobreescribir archivos en caso de que ya existan, etc.
Lista_a_exportar <- list("Cuadro 1.1" = Cuadro_1.1a,
"Cuadro 1.2" = Cuadro_1.2a)
# write.xlsx(Lista_a_exportar,"../Resultados/Informe Mercado de Trabajo.xlsx")4.6 Ejercicios para practicar
- Levantar la última base individual de EPH
- Crear un vector llamado Variables que contenga los nombres de las variables de interés que refieren a las siguientes características: - Edad, Sexo, Ingreso de la ocupación principal, Categoría ocupacional, ESTADO, PONDERA y PONDIH
Acotar la Base únicamente a las variables de interés, utilizando el vector Variables
- Calcular las tasas de actividad, empleo y desempleo según sexo, para jóvenes entre 18 y 35 años
- Calcular el salario promedio por sexo, para dos grupos de edad: 18 a 35 años y 36 a 70 años. (Recordatorio: La base debe filtrarse para contener únicamente OCUPADOS ASALARIADOS)
Grabar los resultados en un excel
4.6.1 Ejercicios de tarea
- Replicar el cálculo de las tasas logradas en clase para distintos trimestres, levantando las bases desde el segundo trimestre 2016 hasta la última.
- Tips: juntar las bases con el comando
bind_rows() - Probar con
gather()yspread()como quedan mejor los resultados
- Tips: juntar las bases con el comando
- Grabar los resultados en un excel