7.1 Explicación
7.1.1 Probabilidad
Previo a estudiar las herramientas de la estadística descriptiva, es necesario hacer un breve resumen de algunos conceptos fundamentales de probabilidad
7.1.1.1 Marco conceptual
- El análisis de las probabilidades parte de un proceso generador de datos entendido como cualquier fenómeno que produce algún tipo de información de forma sistemática.
- Cada iteración de este proceso produce información, que podemos interpretar como un resultado.
- Existe un conjunto de posibles resultados, que definimos como espacio muestral.
- Un evento es el conjunto de resultados ocurridos.
- En este marco, la probabilidad es un atributo de los eventos. Es la forma de medir los eventos tal que, siguiendo la definición moderna de probabilidad:
- \(P(A) \geq 0 \ \forall \ A \subseteq \Omega\)
- \(P(\Omega)=1\)
- \(P(A\cup B) = P(A) + P(B)\ si\ A \cap B = \emptyset\)
ejemplo, tiramos un dado y sale tres
- Espacio muestral: 1,2,3,4,5,6
- Resultado: 3
- Evento: impar (el conjunto 1,3,5)
7.1.1.2 Distribución de probabilidad
La distribución de probabilidad hace referencia a los posibles valores teóricos de cada uno de los resultados pertenecientes al espacio muestral.
Existen dos tipos de distribuciones, dependiendo si el espacio muestral es o no numerable.
7.1.1.2.1 Distribuciones discretas
Sigamos con el ejemplo de dado.
Podríamos definir la distribución de probabilidad, si el dado no está cargado, como:
| valor | probabilidad |
|---|---|
| 1 | 1/6 |
| 2 | 1/6 |
| 3 | 1/6 |
| 4 | 1/6 |
| 5 | 1/6 |
| 6 | 1/6 |
Como el conjunto de resultados posibles es acotado, podemos definirlo en una tabla, esta es una distribución discreta.
7.1.1.2.2 Distribuciones continuas
¿Qué pasa cuando el conjunto de resultados posibles es tan grande que no se puede enumerar la probabilidad de cada caso?
Si, por definición o por practicidad, no se puede enumerar cada caso, lo que tenemos es una distribución continua.
Por ejemplo, la altura de la población
En este caso, no podemos definir en una tabla la probabilidad de cada uno de los posibles valores. de hecho, la probabilidad puntual es 0.
Sin embargo, sí podemos definir una función de probabilidad, la densidad.
Según qué función utilicemos, cambiará la forma de la curva.
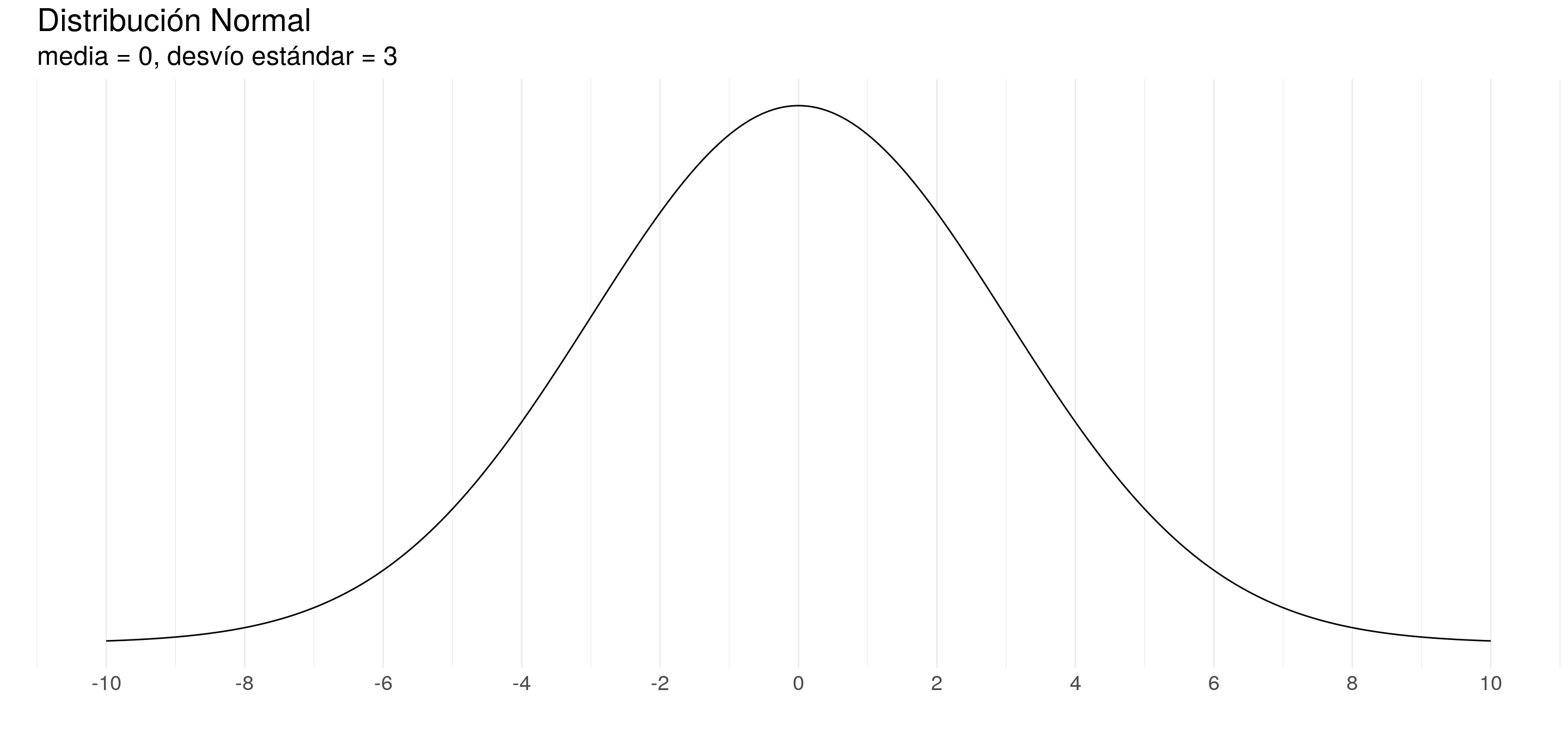
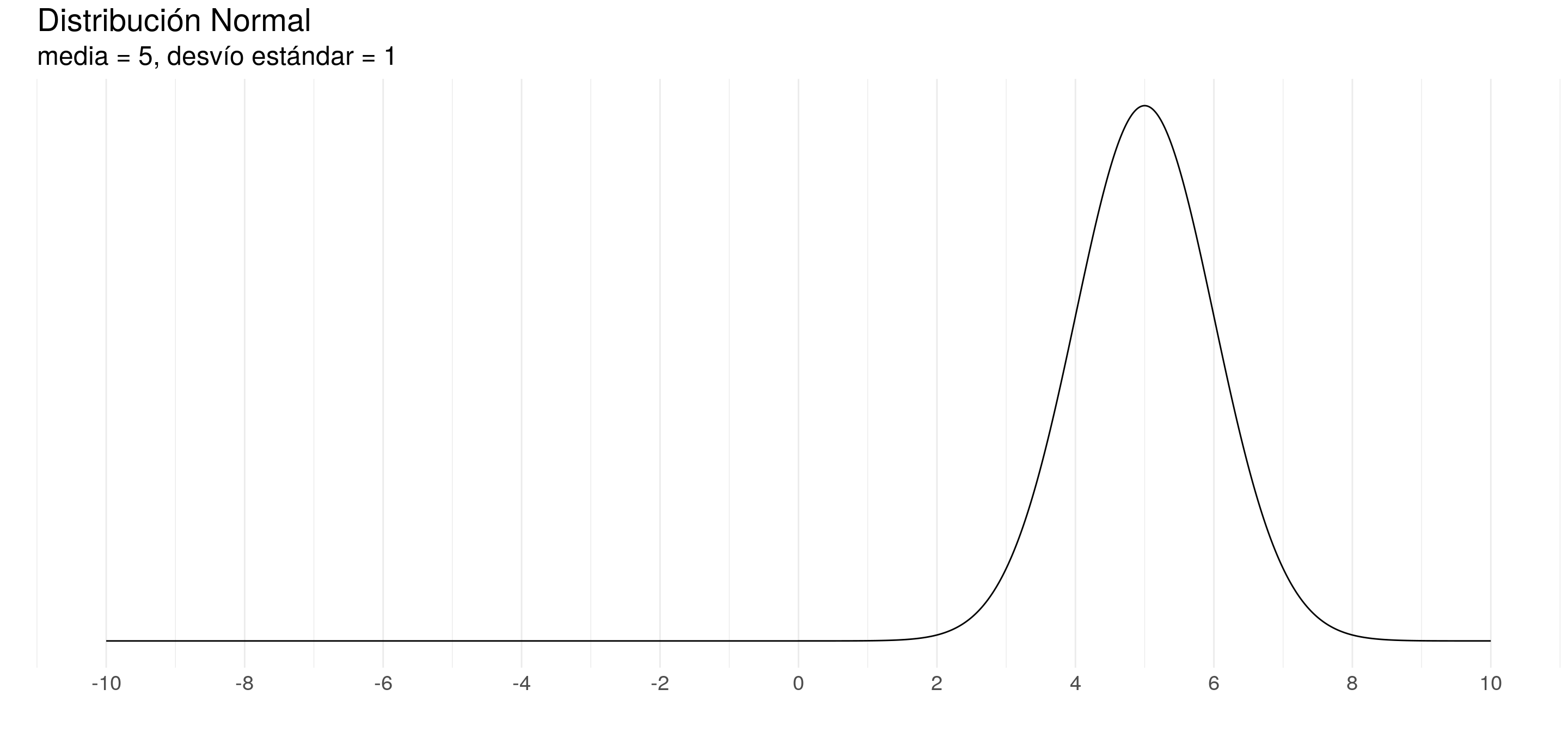
Por ejemplo:

Una distribución de probabilidad se caracteriza por sus parámetros.
- Por ejemplo, la distribución normal se caracteriza por su esperanza y su varianza (o desvío estándar)
7.1.2 Estadística
7.1.2.1 El problema de la inversión
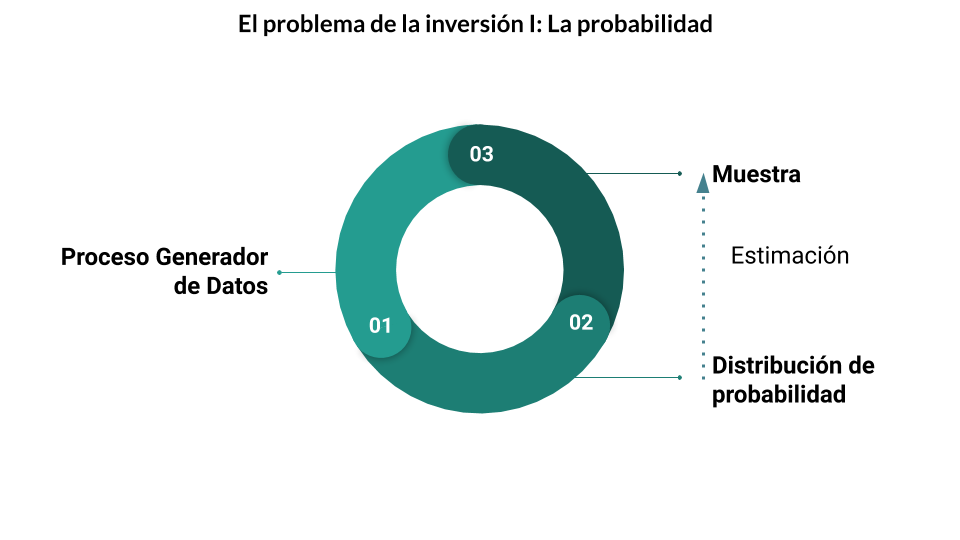
El problema de la probabilidad se podría pensar de la siguiente forma:
- Vamos a partir de un proceso generador de datos
- Para calcular su distribución de probabilidad, los parámetros que caracterizan a ésta, y a partir de allí,
- Calcular la probabilidad de que, al tomar una muestra, tenga ciertos eventos.
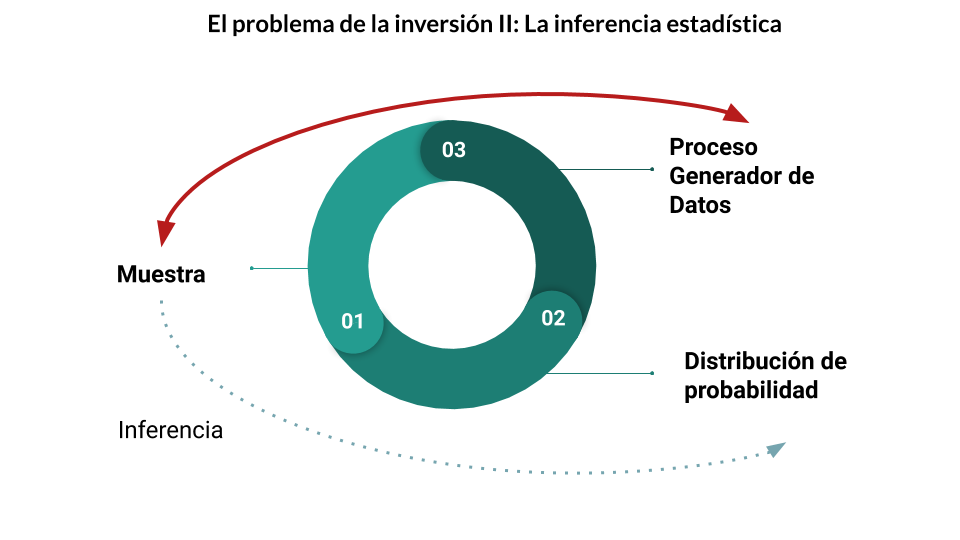
El problema de la estadística es exactamente el contrario:
- Partimos de una muestra para
- Inferir cuál es la distribución de probabilidad, y los parámetros que la caracterizan
- Para finalmente poder sacar conclusiones sobre el proceso generador de datos
7.1.2.1.1 Población y muestra
En este punto podemos hacer la distinción entre población y muestra
- Población: El universo en estudio. Puede ser:
- finita: Los votantes en una elección.
- infinita: El lanzamiento de una moneda.
- Muestra: subconjunto de n observaciones de una población.
Solemos utilizar las mayúsculas (N) para la población y las minúsculas (n) para las muestras
7.1.2.1.2 Parámetros y Estimadores
- Como dijimos, los parámetros describen a la función de probabilidad. Por lo tanto hacen referencia a los atributos de la población. Podemos suponer que son constantes.
- Un estimador es un estadístico (esto es, una función de la muestra) usado para estimar un parámetro desconocido de la población.
7.1.2.1.3 Ejemplo. La media
Esperanza o Media Poblacional:
\[ \mu = E(x)= \sum_{i=1}^N x_ip(x_i) \]
Media muestral:
\[ \bar{X}= \sum_{i=1}^n \frac{Xi}{n} \]
Como no puedo conocer \(\mu\), lo estimo mediante \(\bar{X}\)
7.1.2.2 Estimación puntual, Intervalos de confianza y Tests de hipótesis
El estimador \(\bar{X}\) nos devuelve un número. Esto es una inferencia de cuál creemos que es la media. Pero no es seguro que esa sea realmente la media. Esto es lo que denominamos estimación puntual.
También podemos estimar un intervalo, dentro del cual consideramos que se encuentra la media poblacional. La ventaja de esta metodología es que podemos definir la probabilidad de que el parámetro poblacional realmente esté dentro de este intervalo. Esto se conoce como intervalos de confianza.
Por su parte, también podemos calcular la probabilidad de que el parámetro poblacional sea mayor, menor o igual a un cierto valor. Esto es lo que se conoce como test de hipótesis.
En el fondo, los intervalos de confianza y los tests de hipótesis se construyen de igual manera. Son funciones que se construyen a partir de los datos, que se comparan con distribuciones conocidas, teóricas.
7.1.2.2.1 Definición de los tests
- Los tests se construyen con dos hipótesis: La hipótesis nula \(H_0\), y la hipótesis alternativa, \(H_1\). Lo que buscamos es ver si hay evidencia suficiente para rechazar la hipótesis nula.
Por ejemplo, si queremos comprobar si la media poblacional, \(\mu\) de una distribución es mayor a \(X_i\), haremos un test con las siguientes hipótesis:
- \(H_0: \mu = X_i\)
- \(H_1: \mu > X_i\)
Si la evidencia es lo suficientemente fuerte, podremos rechazar la hipótesis \(H_0\), pero no afirmar la hipótesis \(H_1\)
7.1.2.2.2 Significatividad en los tests
Muchas veces decimos que algo es “estadísticamente significativo”. Detrás de esto se encuentra un test de hipótesis que indica que hay una suficiente significativdad estadística.
La significatividad estadística, representada con \(\alpha\), es la probabilidad de rechazar \(H_0\) cuando en realidad es cierta. Por eso, cuanto más bajo el valor de \(\alpha\), más seguros estamos de no equivocarnos. Por lo general testeamos con valores de alpha de 1%, 5% y 10%, dependiendo del área de estudio.
El p-valor es la mínima significatividad para la que rechazo el test. Es decir, cuanto más bajo es el p-valor, más seguros estamos de rechazar \(H_0\).
El resultado de un test está determinado por:
- La fuerza de la evidencia empírica: Si nuestra duda es si la media poblacional es mayor a, digamos, 10, y la media muestral es 11, no es lo mismo que si es 100, 1000 o 10000.
- El tamaño de la muestra: En las fórmulas que definen los test siempre juega el tamaño de la muestra: cuanto más grande es, más seguros estamos de que el resultado no es producto del mero azar.
- La veracidad de los supuestos: Otra cosa importante es que los test asumen ciertas cosas:
- Normalidad en los datos.
- Que conocemos algún otro parámetro de la distribución, como la varianza.
- Que los datos son independientes entre sí,
- Etc.
Cada Test tiene sus propios supuestos. Por eso a veces, luego de hacer un test, hay que hacer otros tests para validar que los supuestos se cumplen.
Lo primero, la fuerza de la evidencia, es lo que más nos importa, y no hay mucho por hacer.
El tamaño de la muestra es un problema, porque si la muestra es muy chica, entonces podemos no llegar a conclusiones significativas aunque sí ocurra aquello que queríamos probar.
Sin embargo, el verdadero problema en La era del big data es que tenemos muestras demasiado grandes, por lo que cualquier test, por más mínima que sea la diferencia, puede dar significativo.
Por ejemplo, podemos decir que la altura promedio en Argentina es 1,74. Pero si hacemos un test, utilizando como muestra 40 millones de personas, vamos a rechazar que ese es el valor, porque en realidad es 1,7401001. En términos de lo que nos puede interesar, 1,74 sería válido, pero estadísticamente rechazaríamos.
- Finalmente, según la información que tengamos de la población y cuál es el problema que queremos resolver, vamos a tener que utilizar distintos tipos de tests. La cantidad de tests posibles es ENORME, y escapa al contenido de este curso, así como sus fórmulas. A modo de ejemplo, les dejamos el siguiente machete:
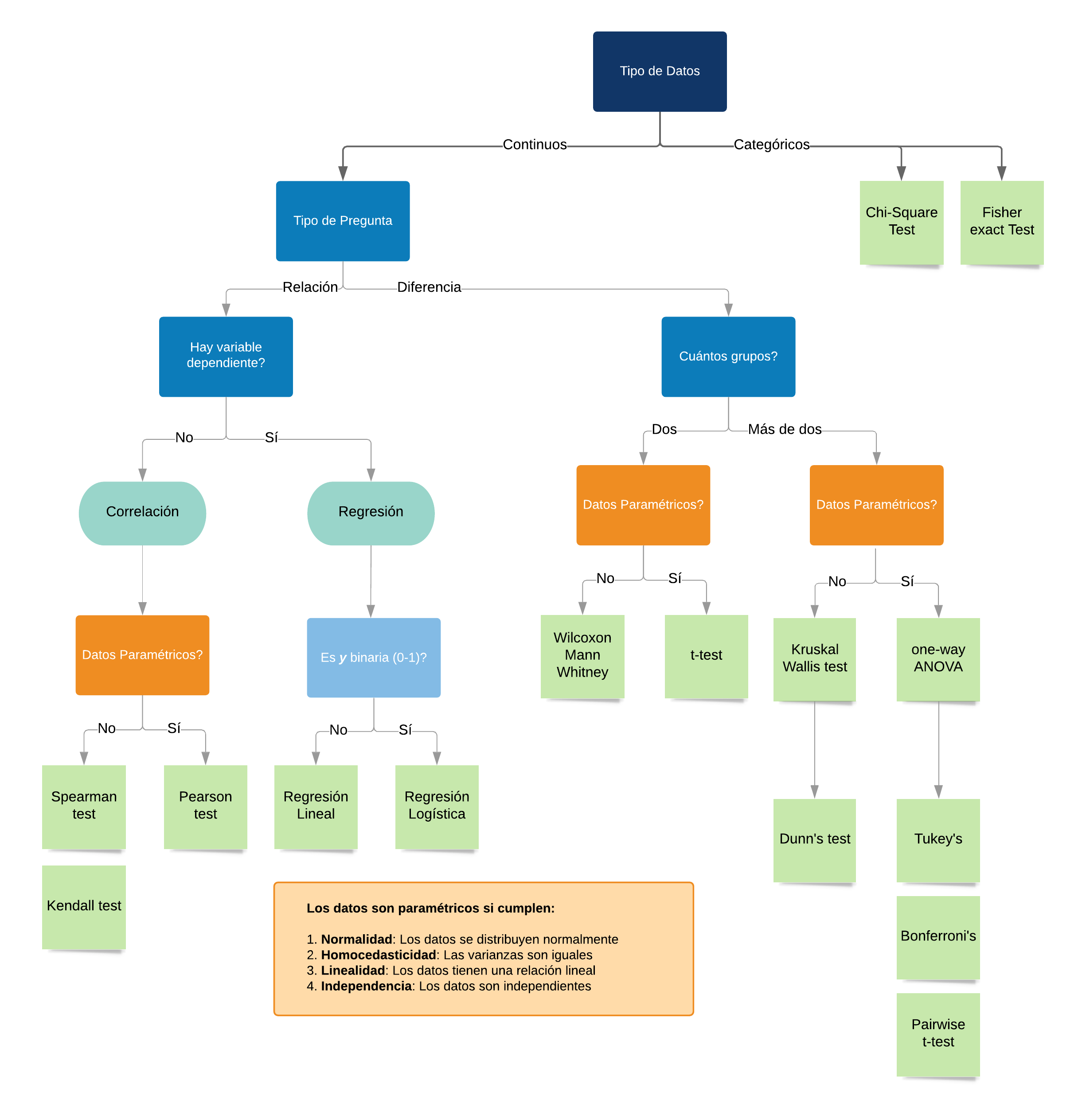
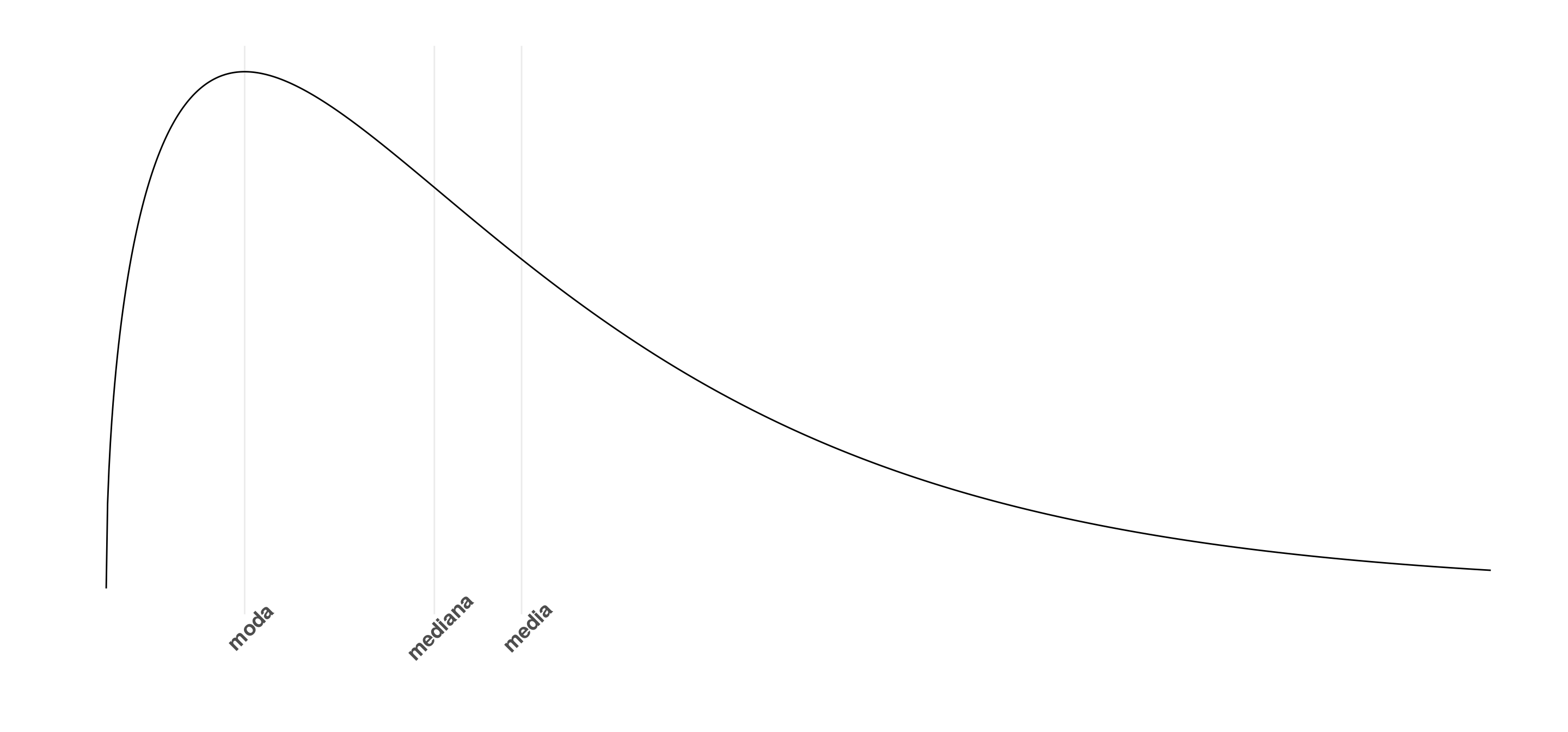
7.1.3 Algunos estimadores importantes
7.1.3.1 Medidas de centralidad
- Media
\[ \bar{X}= \sum_{i=1}^n \frac{Xi}{n} \]
- Mediana:
Es el valor que parte la distribución a la mitad
- Moda
La moda es el valor más frecuente de la distribución
7.1.3.2 Cuantiles
Así como dijimos que la mediana es el valor que deja al 50% de los datos de un lado y al 50% del otro, podemos generalizar este concepto a cualquier X%. Esto son los cuantiles. El cuantil x, es el valor tal que queda un x% de la distribución a izquierda, y 1-x a derecha.
Algunos de los más utilizados son el del 25%, también conocido como \(Q_1\) (el cuartil 1), el \(Q_2\) (la mediana) y el \(Q_3\) (el cuartil 3), que deja el 75% de los datos a su derecha. Veamos cómo se ven en la distribución de arriba.
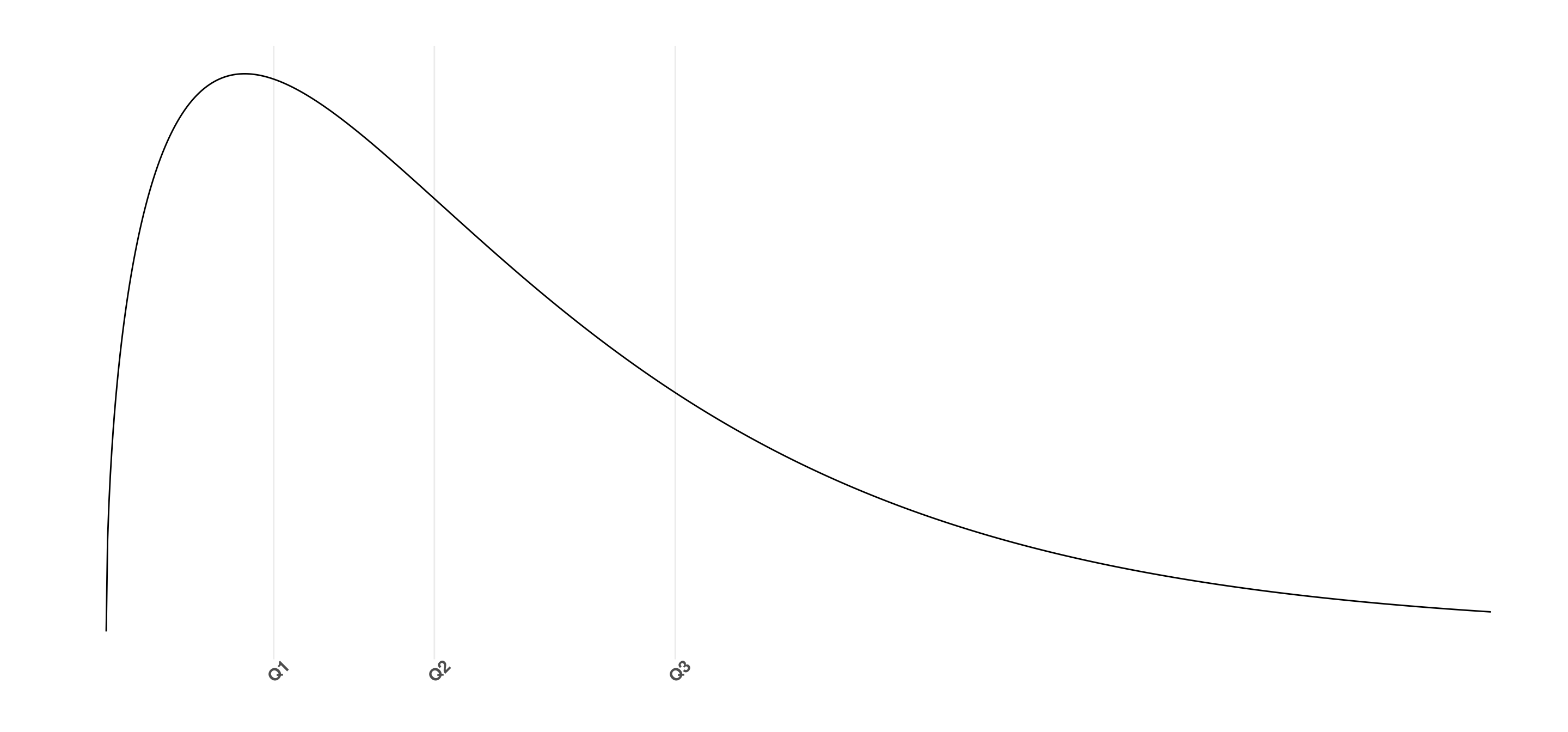
7.1.3.3 Desvío estándar
- El desvío estándar es una medida de dispersión de los datos, que indica cuánto se suelen alejar de la media.
7.1.4 Gráficos estadísticos
Cerramos la explicación con algunos gráficos que resultan útiles para entender las propiedades estadísticas de los datos.
7.1.4.1 Boxplot
El Boxplot es muy útil para describir una distribución y para detectar outliers. Reúne los principales valores que caracterizan a una distribución:
- \(Q_1\)
- \(Q_2\) (la mediana)
- \(Q_3\)
- el rango intercuarítlico \(Q_3 - Q_1\), que define el centro de la distribución
- Outliers, definidos como aquellos puntos que se encuentran a más de 1,5 veces el rango intercuartílico del centro de la distribución.
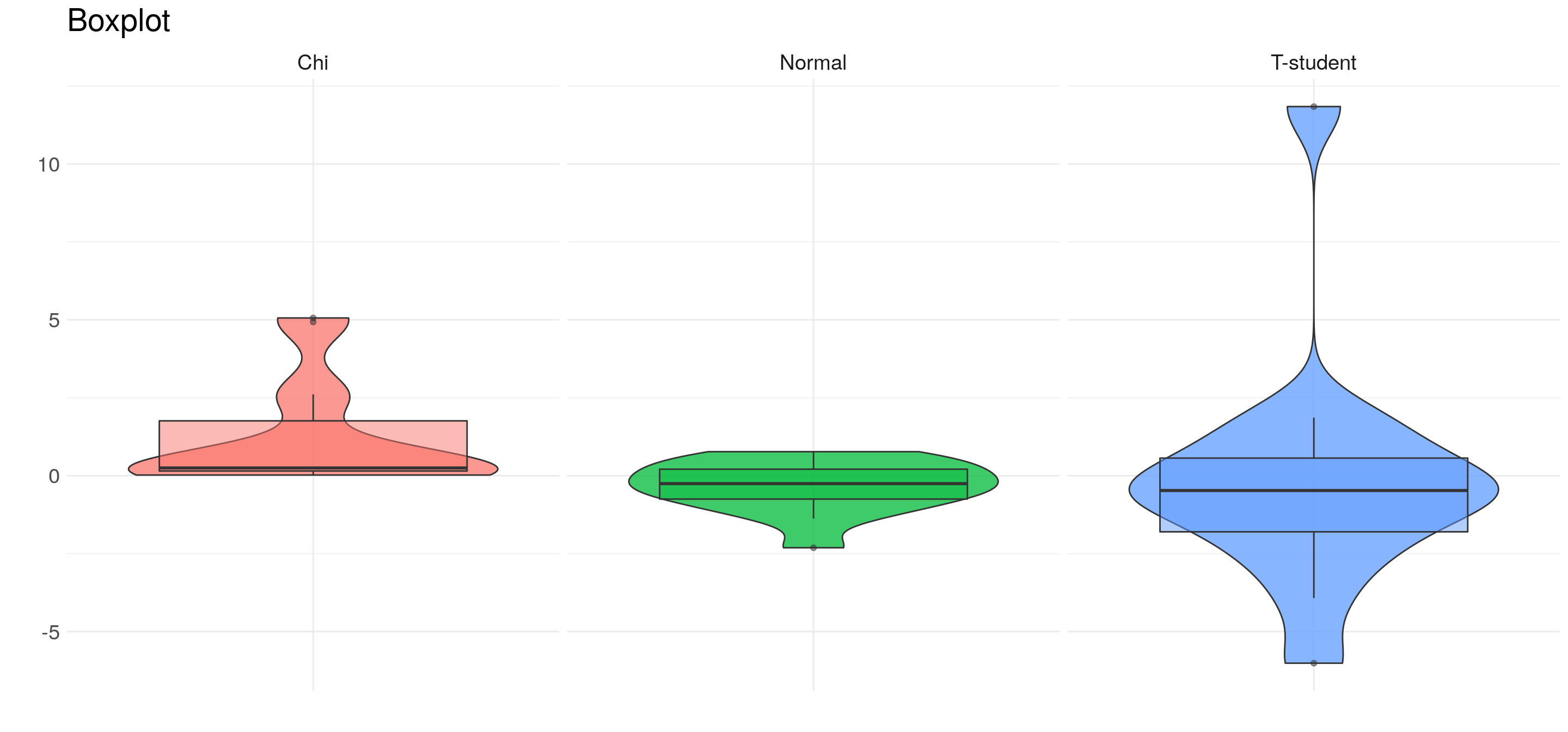
Veamos qué pinta tienen los boxplot de números generados aleatoriamente a partir de tres distribuciones que ya vimos. En este caso, sólo tomaremos 15 valores de cada distribución
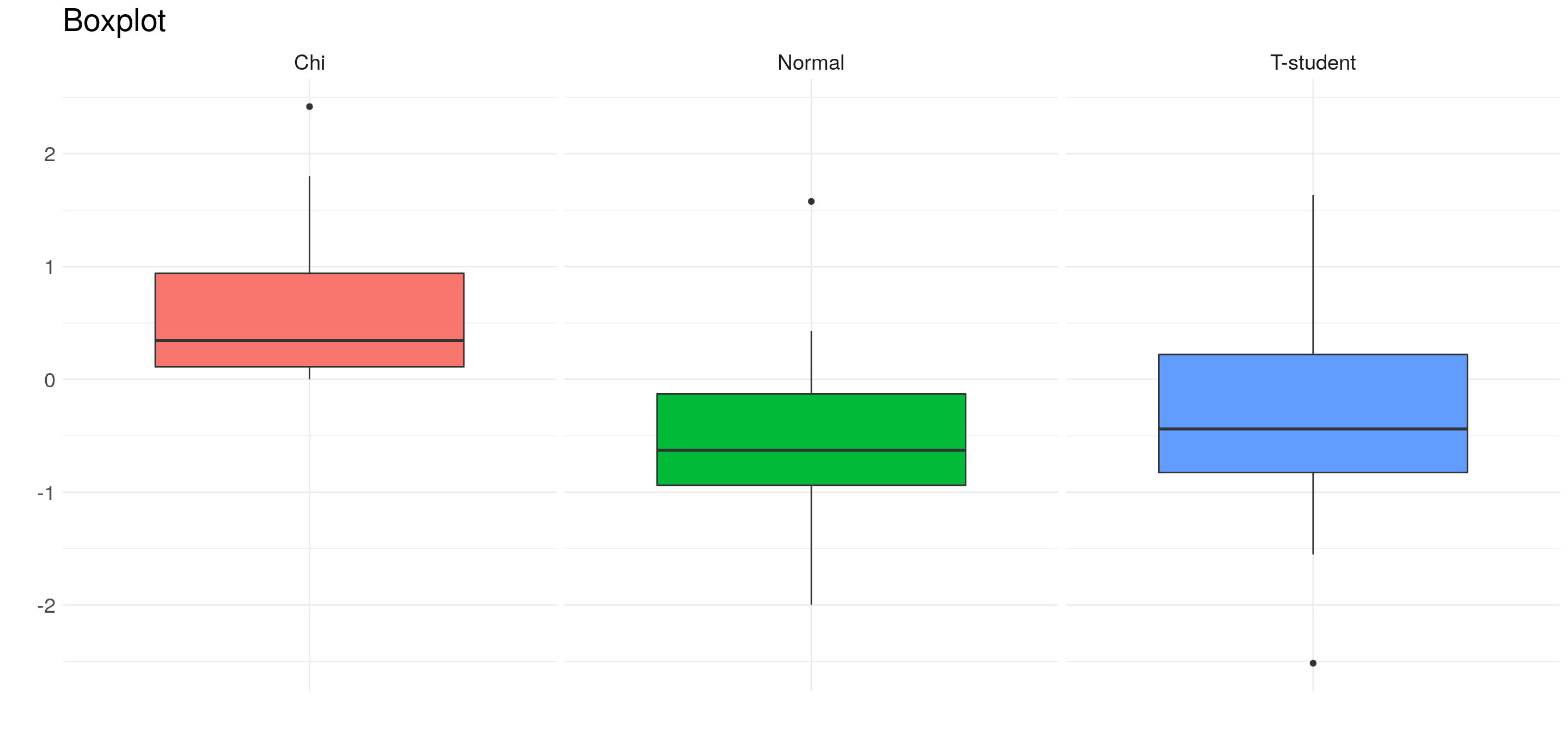
Algunas cosas que resaltan:
- la distribución \(\chi^2\) no toma valores en los negativos.
- La normal esta más concentrada en el centro de la distribución.
Podemos generar 100 números aleatorios en lugar de 15:
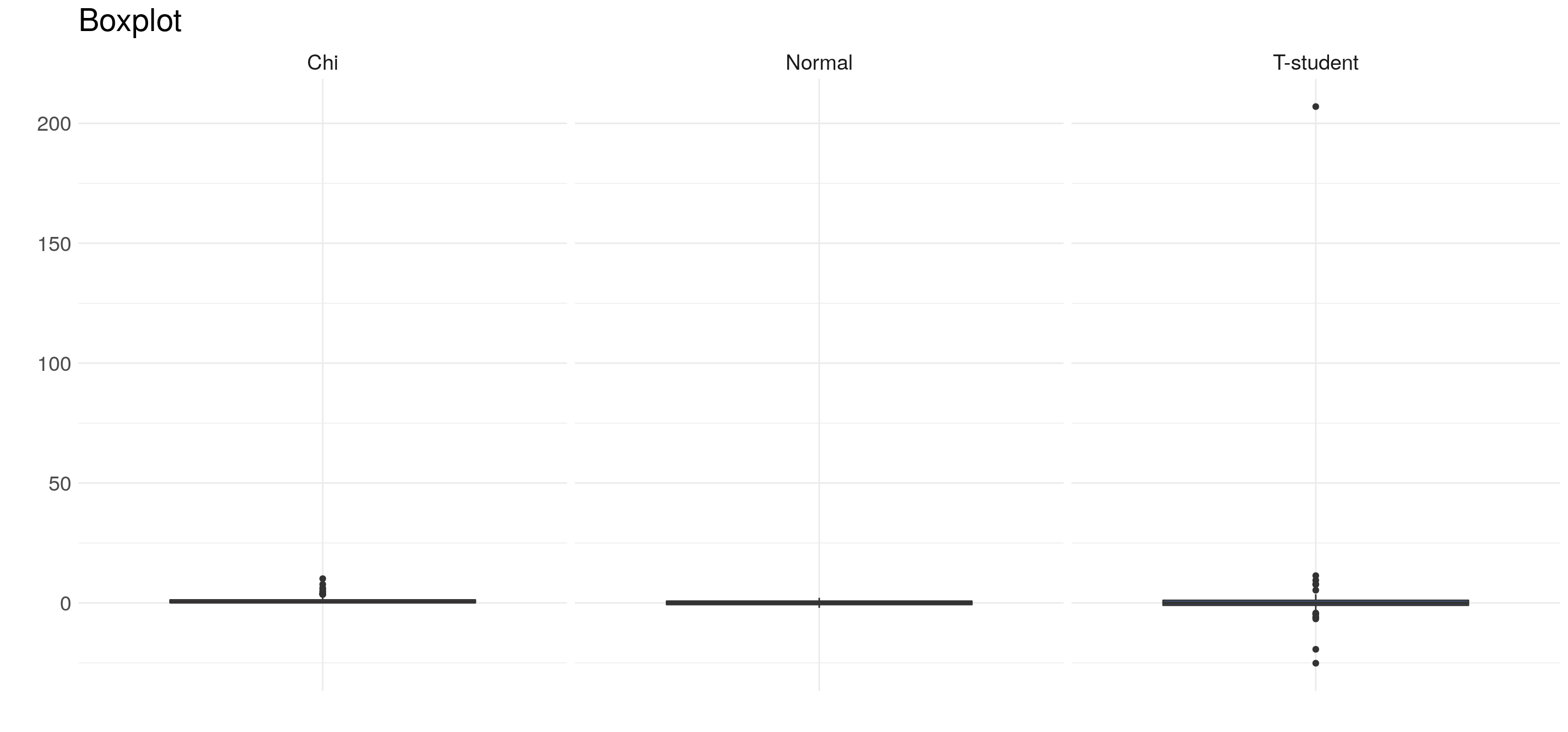
Cuando generamos 100 valores en lugar de 15, tenemos más chances de agarrar un punto alejado en la distribución. De esta forma podemos apreciar las diferencias entre la distribución normal y la T-student.
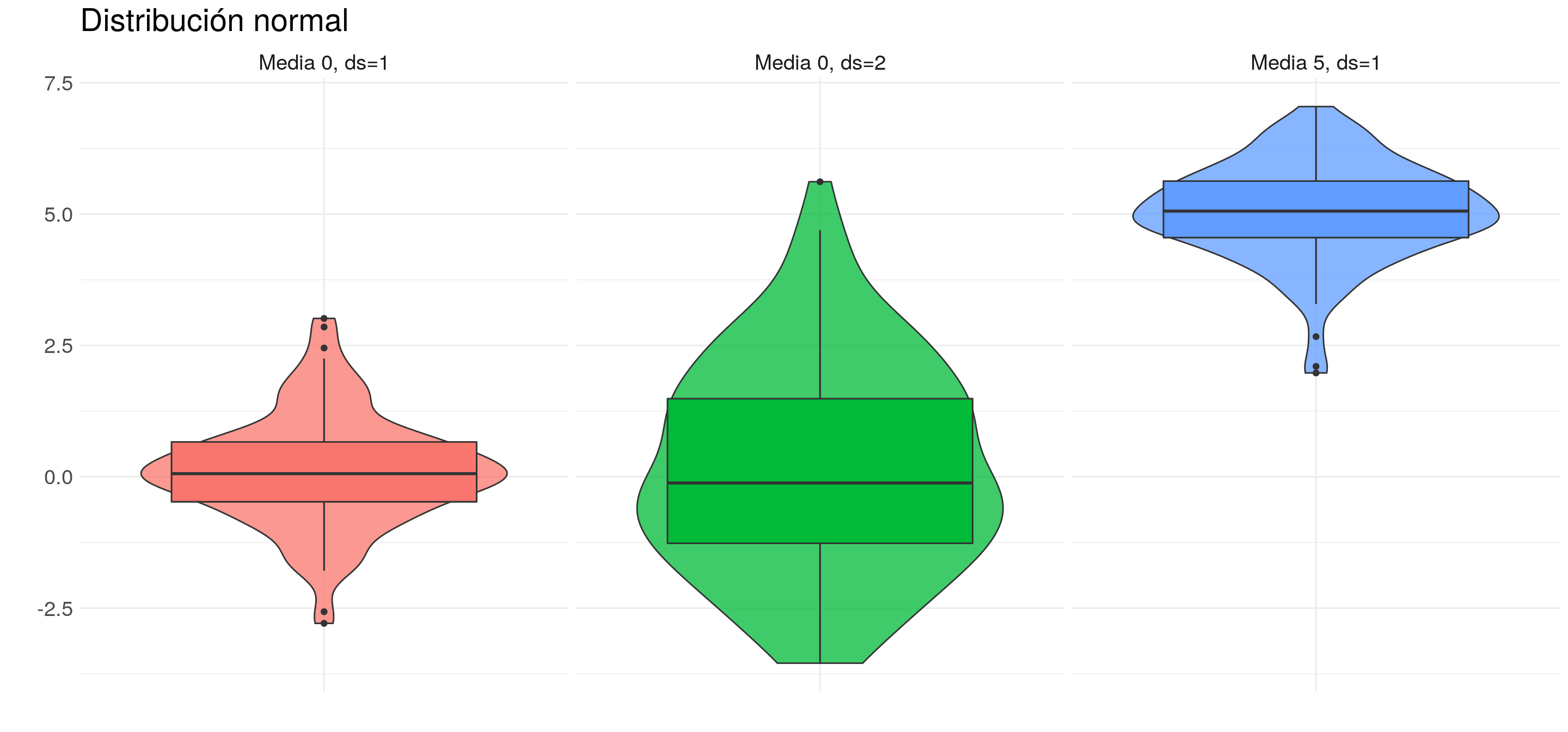
También podemos volver a repasar qué efecto generan los distintos parámetros. Por ejemplo:
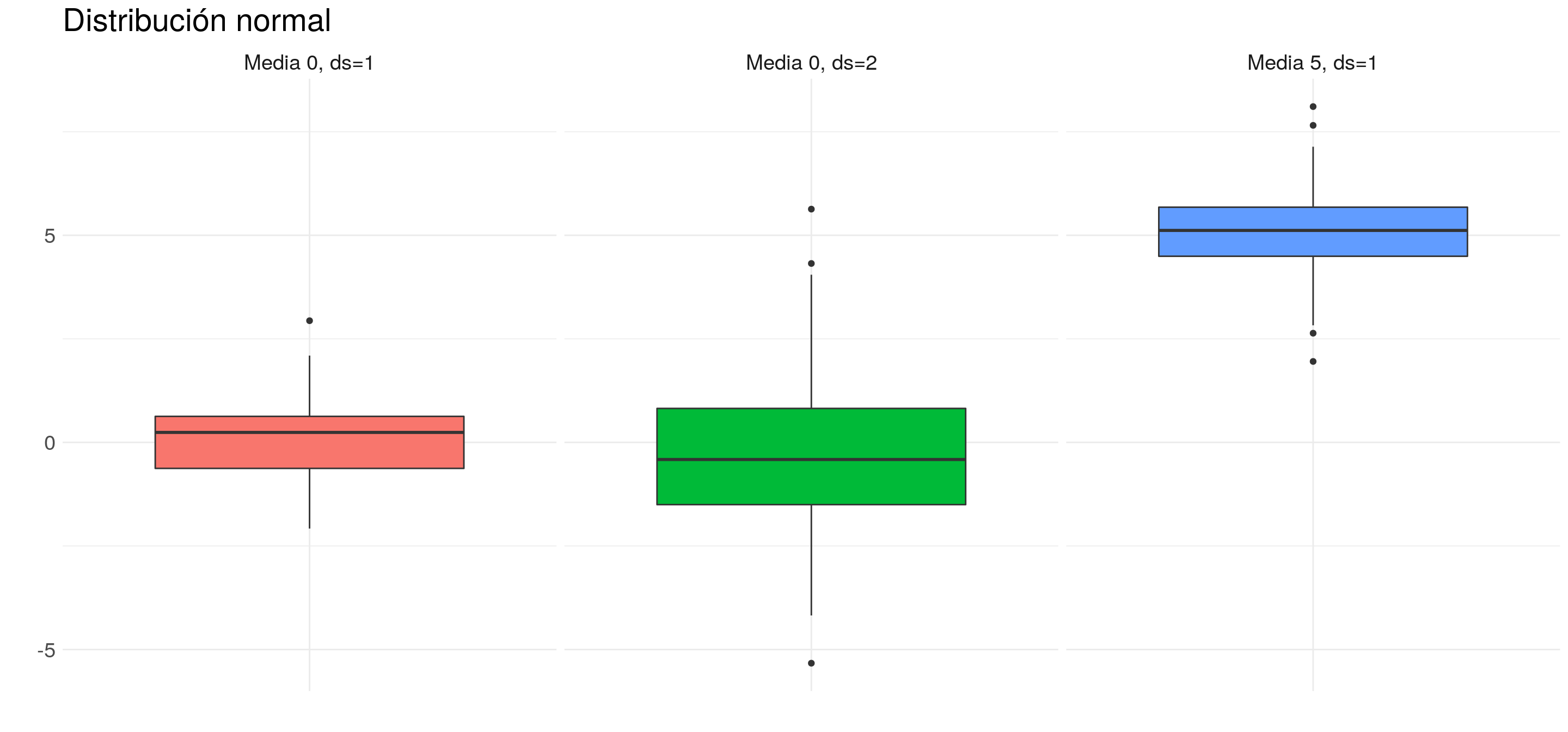
7.1.4.2 Histograma
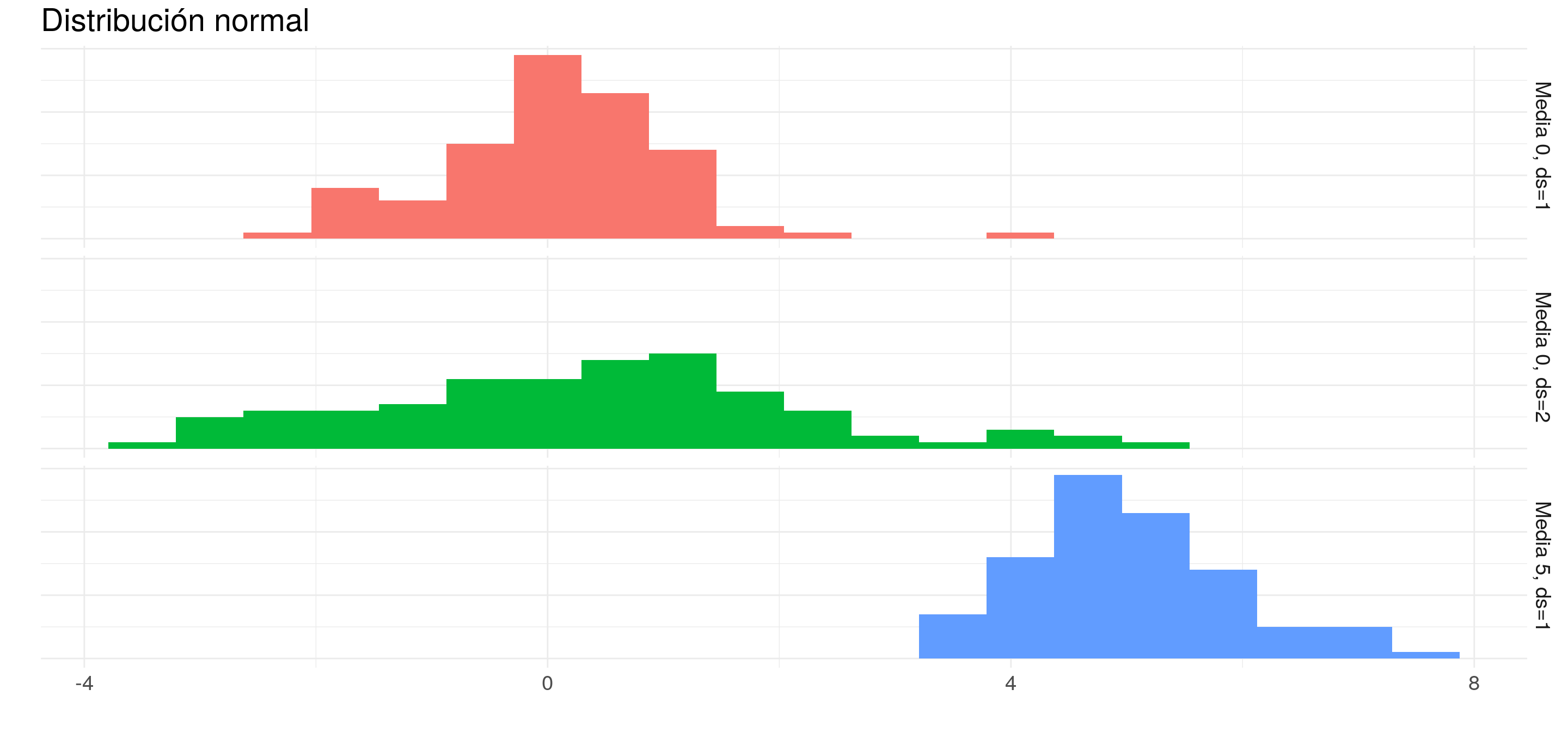
Otra forma de analizar una distribución es mediante los histogramas:
- En un histograma agrupamos las observaciones en rangos fijos de la variable y contamos la cantidad de ocurrencias.
- Cuanto más alta es una barra, es porque más observaciones se encuentran en dicho rango.
Veamos el mismo ejemplo que arriba, pero con histogramas:

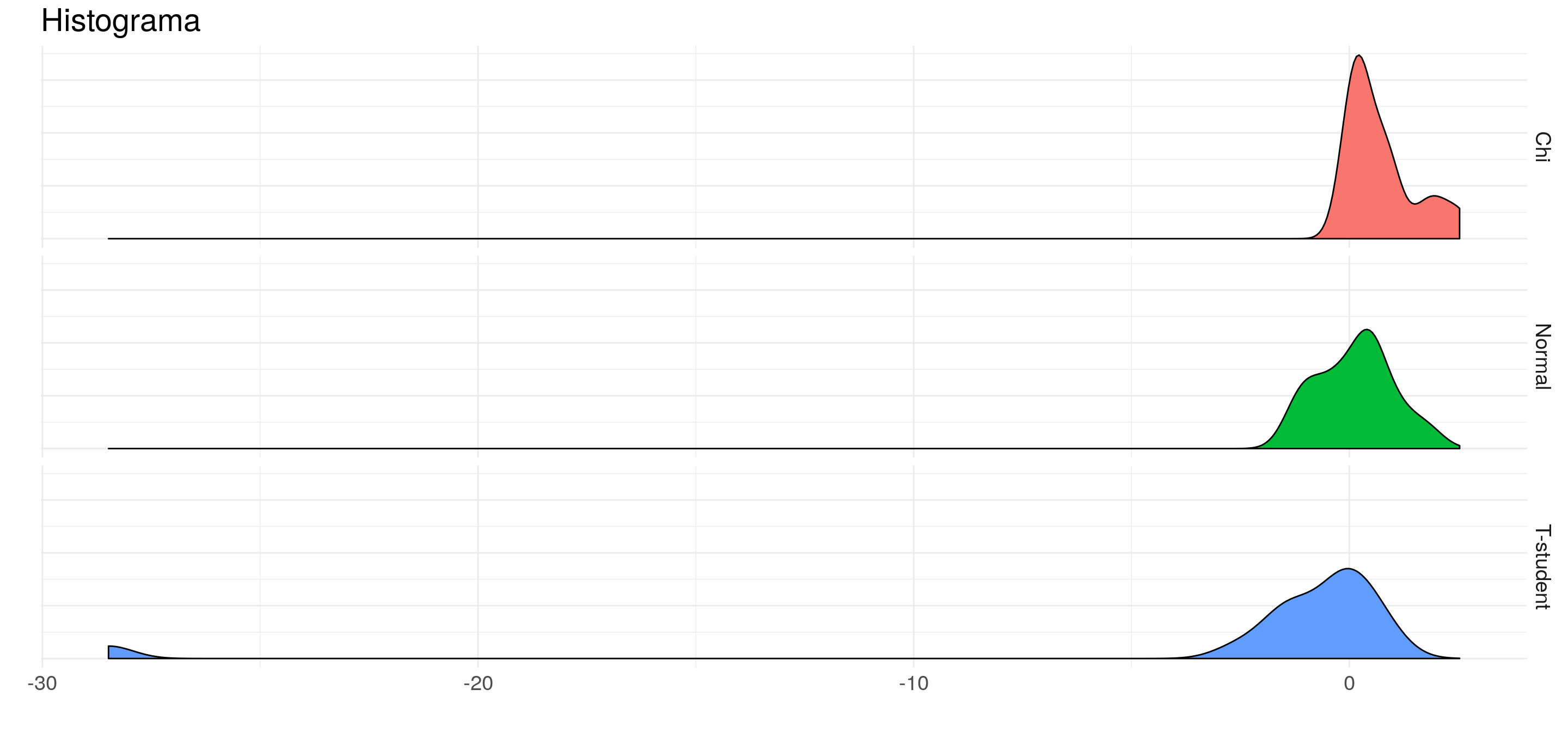
7.1.4.3 Kernel
Los Kernels son simplemente un suavizado sobre los histogramas.
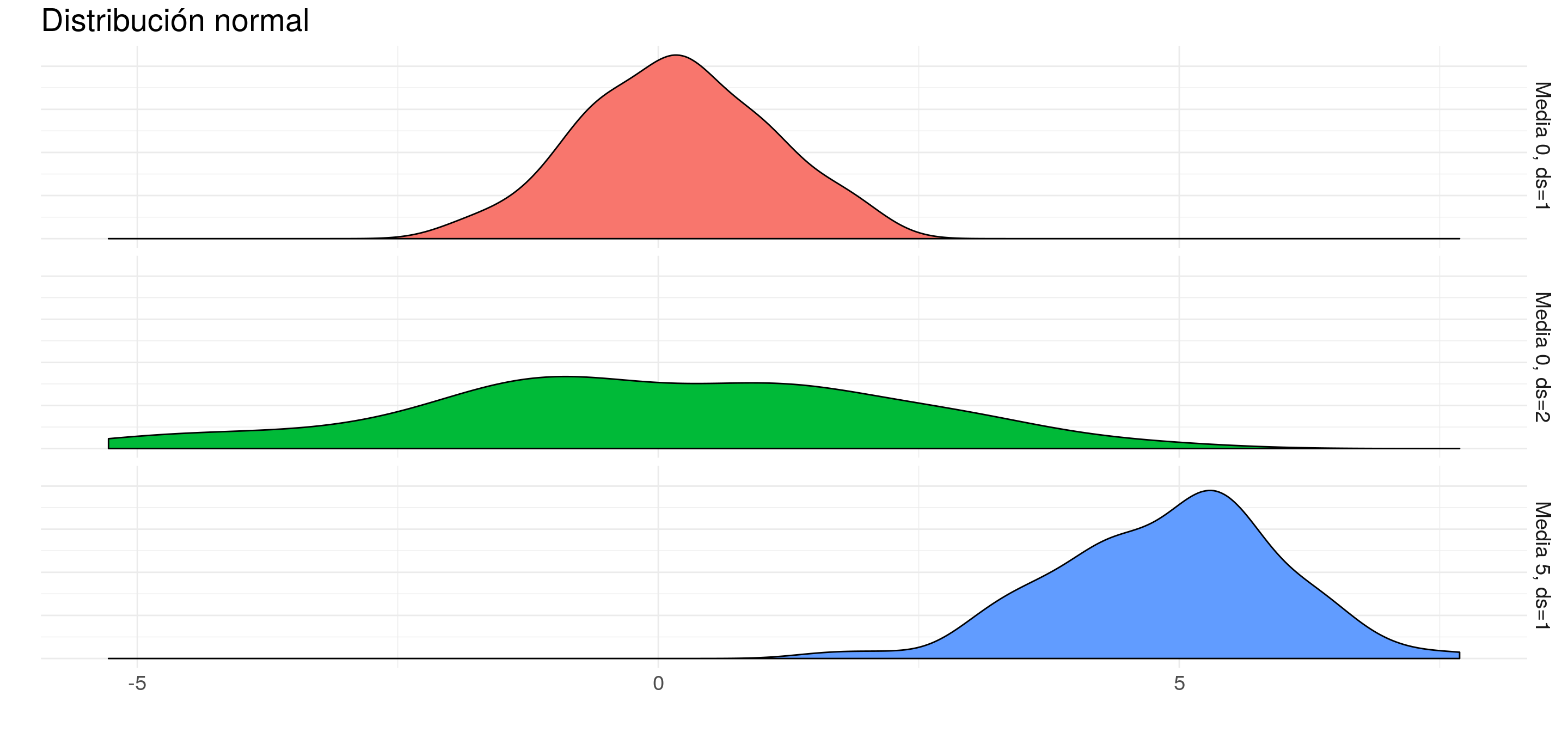
7.1.4.4 Violin plots
Combinando la idea de Kernels y Boxplots, se crearon los violin plots, que simplemente muestran a los kernels duplicados.
7.1.5 Bibliografía de consulta
Quién quiera profundizar en estos temas, puede ver los siguientes materiales:
- https://seeing-theory.brown.edu/
- https://lagunita.stanford.edu/courses/course-v1:OLI+ProbStat+Open_Jan2017/about
- Jay L. Devore, “Probabilidad y Estadística para Ingeniería y Ciencias”, International Thomson Editores. https://inferencialitm.files.wordpress.com/2018/04/probabilidad-y-estadistica-para-ingenieria-y-ciencias-devore-7th.pdf