10.1 Explicación

10.1.1 Introducción
Junto con las imágenes y los audios, los textos son una fuente de datos no estructurados que se multiplicó en los últimos años.
Para poder hacer uso de la información que contienen es necesario procesar los documentos originales a un formato lo suficientemente estandarizado como para que pueda alimentar algún tipo de modelo
En la clase de hoy veremos un repaso de algunas de las técnicas más usuales para normalizar la información de documentos.
10.1.2 Bag of Words
Los documentos se pueden caracterizar por las palabras que contienen. Esto esconde el supuesto fuerte de independencia. No estamos considerando el orden
Para este tipo de técnicas, una buena representación de la información es una bolsa de palabras. Un formato que indica la cantidad de veces que aparece una palabra en un documento.
También se conocen como Matrices Documento-Término o Término-Documento, según la orientación
Ejemplo: opiniones de trip advisor:
library(tidyverse)
library(tm)
doc1='Lugar espectacular e inolvidable'
doc2='Precioso lugar, la comida era espectacular, de 10, precioso!'
texto <- c(doc1,doc2)
myCorpus = VCorpus(VectorSource(texto))
myDTM = DocumentTermMatrix(myCorpus, control = list(minWordLength = 1))
m = as.matrix(myDTM)
m## Terms
## Docs 10, comida era espectacular espectacular, inolvidable lugar lugar,
## 1 0 0 0 1 0 1 1 0
## 2 1 1 1 0 1 0 0 1
## Terms
## Docs precioso precioso!
## 1 0 0
## 2 1 1
Nosotros sabemos que el significado de “lugar” y “lugar,” es el mismo
Al no estar normalizada la información, la BoW genera matrices muy grandes y esparsas, que son poco útiles para trabajar
10.1.3 Normalización
Para construir el Bag of Words se debe considerar los siguientes procesos:
Tokenization: Es el proceso de partir un string de texto en palabras y signos de puntuación.
Eliminar puntuación.
Stop Words: remover las palabras más comunes del idioma (“el”, “la”, “los”, “de”) ya que aparecen en todos los documentos y no aportan información valiosa para distinguirlos.
Lemmatization: Es la representación de todas las formas flexionadas (plural, femenino, conjugado, etc.). Para esto, es necesario contar con una base de datos léxica. Para esto podemos usar koRpus que incluye el lexicón TreeTagger.
Stemming: Es similar a la lematización, pero no se basa en las estructuras lexicales, sino que realiza una aproximación, quedándose con las primeras letras de la palabra.
- N-gramas: A veces los conceptos que permiten distinguir entre documentos se componen de más de una palabra, por ejemplo:
- “a duras penas” (trigrama),
- “Buenos Aires” (bigrama)
- Las expresiones idiomáticas o los nombres propios cambian radicalmente de sentido si se separan sus componentes.
- Imaginense si quisiéramos clasificar la posición política de izquierda a derecha de los “Nacional Socialistas”!
Ejemplo: Limpiando el texto:
doc1='Lugar espectacular e inolvidable'
doc2='Precioso lugar, la comida era espectacular, de 10, precioso!'
texto <- c(doc1,doc2)
myCorpus = VCorpus(VectorSource(texto))
myCorpus = tm_map(myCorpus, content_transformer(tolower))
myCorpus = tm_map(myCorpus, removePunctuation)
myCorpus = tm_map(myCorpus, removeNumbers)
myCorpus = tm_map(myCorpus, removeWords, stopwords(kind = "es"))
myDTM = DocumentTermMatrix(myCorpus, control = list(minWordLength = 1))
m = as.matrix(myDTM)
m## Terms
## Docs comida espectacular inolvidable lugar precioso
## 1 0 1 1 1 0
## 2 1 1 0 1 210.1.4 Expresiones regulares.
Un elemento fundamental para la manipulación del texto son las expresiones regulares. Éstas sirven para captar patrones que aparecen en el texto y luego operar sobre ellos (extraerlos, reemplazarlos, detectarlos, etc.)
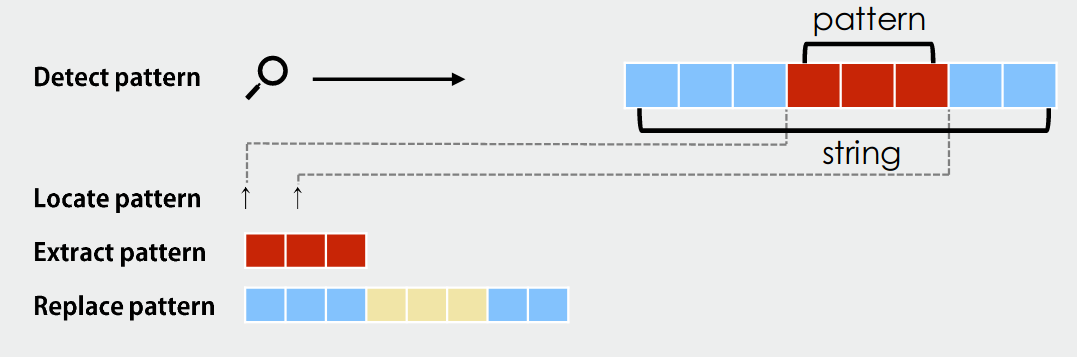
por ejemplo
## [1] TRUEPara generar una expresión regular, utilizamos distintos elementos:
10.1.4.1 Caracteres especiales.
Son formas de referirnos a tipos de caracteres

por ejemplo
## [1] FALSE## [1] TRUE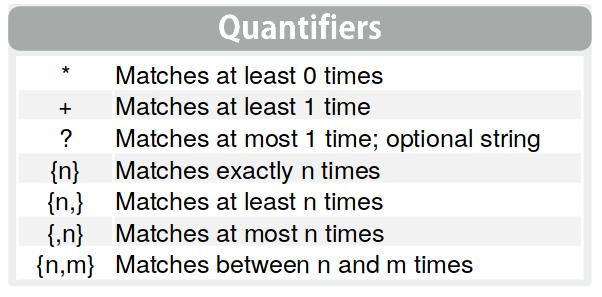
Los cuantificadores nos permiten decír “Este caracter, X veces”
por ejemplo
## [1] 31## [1] TRUE## [1] FALSEEsto se lee como “caracteres de palabras (a,b,c…z ; A,B,C… Z ; 0,1,2..9) ó otros caracteres distintos, entre 29 y 33 veces”.
A veces para extraer pedazos de texto nos conviene chequear que hay antes y después. Eso lo hacemos con los lookarounds
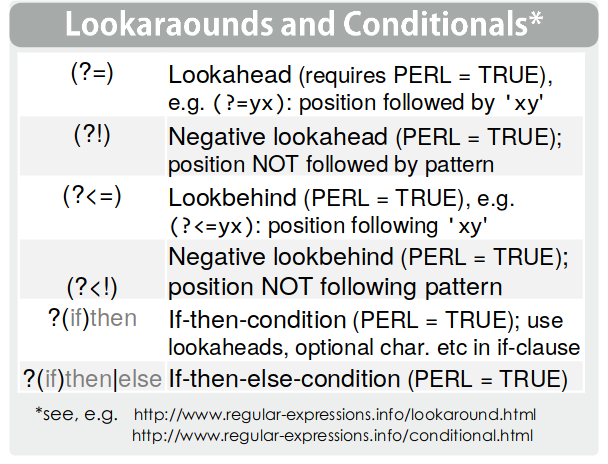
Por ejemplo, si queremos recuerar el DNI de la persona entre muchas otras palabras:
texto_con_dni <- 'Lorem ipsum dolor sit amet, DNI 38765239,faucibus et dui tellus, eros mi elit...'
str_extract(texto_con_dni, pattern = '(?<=DNI )\\d{3,}')## [1] "38765239"el patrón se lee “Luego de DNI tres o más dígitos”
10.1.5 Distancia de palabras
La distancia de palabras se puede entender desde distintos lugares:
- Distancia de caracteres: Refiere a la similitud de escritura “Mueve” vs “Nueve”
- Distancia conceptual: Refiere a la similitud del concepto: “Perro” vs “Labrador”
10.1.5.1 Distancia de caracteres
Distancia de Levenshtein o distancia de edición es el número mínimo de operaciones requeridas para transformar una cadena de caracteres en otra. Una operación puede ser una inserción, eliminación o sustitución de un carácter.
Jaro Winkler: Esta medida de similitud da mejores puntajes a los strings que son similares en el principio de la oración. \(0 < sim_{jw}<1\), donde 1 significa que las palabras son idénticas (excepto que p=0.25 y compartan los primeros 4 caracteres). y 0 significa que no se parecen en nada
10.1.5.2 Distancia Conceptual
Word Embeddings: Son una representación vectorial de las palabras que se construye a partir de observar una gran cantidad de documentos.
Word2Vec fue la primera implementación de esta idea. Se entrena una red neuronal para predecir el contexto de una palabra, y luego se utiliza una matriz que se construye dentro de la red como representación de las palabras.
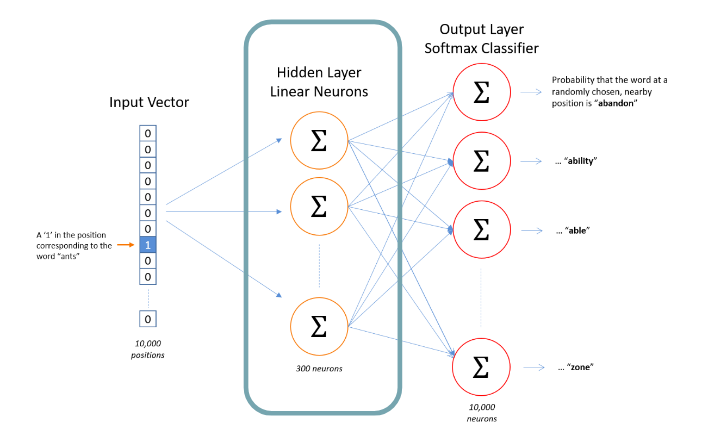
ejemplo: Proyección en tres dimensiones
10.1.6 Distancia de Documentos
10.1.6.1 Similitud Coseno
En el modelo de BoW representamos a todos los documentos como vectores n-dimensionales que toman valores en el espacio de los números enteros.
La dimensión n del espacio está determinada por lo largo del vocabulario utilizado en el corpus.
Para comparar la similitud entre dos documentos, podemos utilizar la similitud coseno entre sus representaciones vectoriales. Intuitivamente, la similitud coseno es una medida de correlación de vectores que representan atributos en lugar de variables que se mueven en un espacio continuo.
recordemos primero algunas definiciones.
El producto interno entre dos vectores x,y se define como:
\[ \langle x,y \rangle=\sum_i x_i y_i = \|x\|\ \|y\|\cos(\theta) \]
Por su parte, la norma 2 de un vector x se define como:
\[ ||x||=\sqrt{\sum_i x^2_i} \]
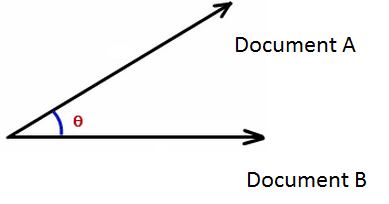
\[ CosSim(x,y) = \frac{\langle x,y \rangle}{\|x\|\ \|y\|} = \frac{\sum_i x_iy_i}{\sum_i x^2_i\sum_i y^2_i} \]
Cuantas más palabras compartan los documentos, mayor es el producto punto. Este a su vez se normaliza por el tamaño de cada documento.
Este valor va de 1 para los documentos son identicos a 0 cuando son totalmente distintos.
10.1.7 Topic Modelling
Las técincas de Modelado de Tópicos tratan de captar los temas de los que habla un corpus de texto.
- Una de las técnicas más difundidas en la actualidad es Latent Dirichlet Allocation Models
Éste es un modelo inferencial bayesiano. No vamos a poder estdiar el detalle del modelo en este curso, pero a grandes rasgos propone un proceso generativo donde cada palabra es el resultado de un encadenamiento de distribuciones, y luego se realiza inferencia hacia atrás para calcular la distribución más probable dada las palabras y los documentos
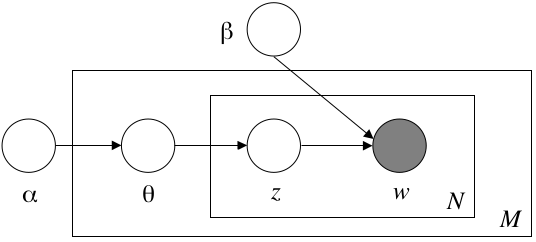
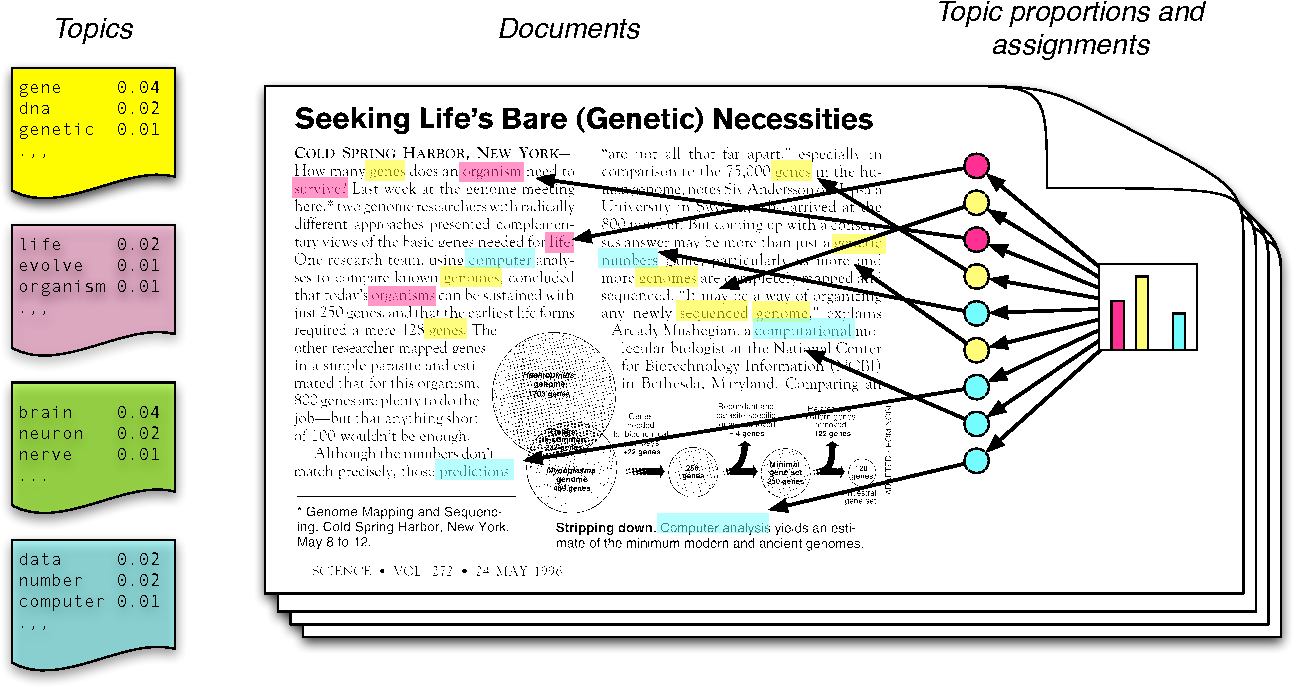
El resultado del modelo es:
- Una distribución de palabras por tópico: Podemos caracterizar cada tópico por sus palabras más importantes.
- Una distribución de los tópicos por documento: Podemos caracterizar un documento por sus temas más importantes
10.1.8 Descargas de tweets con rtweet
rt <- search_tweets(q = "metrovias OR bondi OR Subte OR autopista OR transporte público",type = "mixed", n = 18000, include_rts = FALSE,
lang='es')
saveRDS(rt,'fuentes/rt.RDS')## # A tibble: 10 x 90
## user_id status_id created_at screen_name text source
## <chr> <chr> <dttm> <chr> <chr> <chr>
## 1 163714… 11729330… 2019-09-14 18:00:03 EsDiarioPo… Huel… EsDia…
## 2 301177… 11740080… 2019-09-17 17:11:37 Kisachang Tran… Twitt…
## 3 150072… 11743187… 2019-09-18 13:46:13 ElNacional… "#EN… Tweet…
## 4 111495… 11751529… 2019-09-20 21:01:13 LuisReinaCh Este… Twitt…
## 5 278348… 11747051… 2019-09-19 15:21:48 abcdezihua Usua… IFTTT
## 6 333414… 11751009… 2019-09-20 17:34:23 sofidlm Mi f… Twitt…
## 7 164933… 11746525… 2019-09-19 11:52:55 pabloperoz… Tend… Twitt…
## 8 432293… 11751127… 2019-09-20 18:21:18 Lolibaez La g… Twitt…
## 9 712042… 11744812… 2019-09-19 00:31:57 OaxIndepen… Apru… Twitt…
## 10 103788… 11725858… 2019-09-13 19:00:38 ferrosarmi… ⚠️ #… NAC C…
## # … with 84 more variables: display_text_width <dbl>,
## # reply_to_status_id <chr>, reply_to_user_id <chr>,
## # reply_to_screen_name <chr>, is_quote <lgl>, is_retweet <lgl>,
## # favorite_count <int>, retweet_count <int>, quote_count <int>,
## # reply_count <int>, hashtags <list>, symbols <list>, urls_url <list>,
## # urls_t.co <list>, urls_expanded_url <list>, media_url <list>,
## # media_t.co <list>, media_expanded_url <list>, media_type <list>,
## # ext_media_url <list>, ext_media_t.co <list>,
## # ext_media_expanded_url <list>, ext_media_type <chr>,
## # mentions_user_id <list>, mentions_screen_name <list>, lang <chr>,
## # quoted_status_id <chr>, quoted_text <chr>, quoted_created_at <dttm>,
## # quoted_source <chr>, quoted_favorite_count <int>,
## # quoted_retweet_count <int>, quoted_user_id <chr>,
## # quoted_screen_name <chr>, quoted_name <chr>,
## # quoted_followers_count <int>, quoted_friends_count <int>,
## # quoted_statuses_count <int>, quoted_location <chr>,
## # quoted_description <chr>, quoted_verified <lgl>,
## # retweet_status_id <chr>, retweet_text <chr>,
## # retweet_created_at <dttm>, retweet_source <chr>,
## # retweet_favorite_count <int>, retweet_retweet_count <int>,
## # retweet_user_id <chr>, retweet_screen_name <chr>, retweet_name <chr>,
## # retweet_followers_count <int>, retweet_friends_count <int>,
## # retweet_statuses_count <int>, retweet_location <chr>,
## # retweet_description <chr>, retweet_verified <lgl>, place_url <chr>,
## # place_name <chr>, place_full_name <chr>, place_type <chr>,
## # country <chr>, country_code <chr>, geo_coords <list>,
## # coords_coords <list>, bbox_coords <list>, status_url <chr>,
## # name <chr>, location <chr>, description <chr>, url <chr>,
## # protected <lgl>, followers_count <int>, friends_count <int>,
## # listed_count <int>, statuses_count <int>, favourites_count <int>,
## # account_created_at <dttm>, verified <lgl>, profile_url <chr>,
## # profile_expanded_url <chr>, account_lang <lgl>,
## # profile_banner_url <chr>, profile_background_url <chr>,
## # profile_image_url <chr>## [1] "2019-09-13 03:04:47 UTC" "2019-09-21 18:24:56 UTC"Nos da los tweets de los últimos nueve días, o el máximo que indicamos más reciente
rt %>%
ts_plot("3 hours") +
ggplot2::theme_minimal() +
ggplot2::theme(plot.title = ggplot2::element_text(face = "bold")) +
ggplot2::labs(
x = NULL, y = NULL,
title = "Frecuencia de los tweets relacionados al tránsito",
subtitle = "Agregado a intervalos de tres horas")
- Me quedo con el texto
## [1] "▶ Dos sujetos robaron a usuarios de un vehículo de transporte público https://t.co/3c0fSjKrWF https://t.co/uGYN8CyLuZ"
## [2] "Detienen a dos menores por asalto a transporte público https://t.co/R2VNKPLV0v https://t.co/MOVow5LUiE"
## [3] "Detienen a dos menores por asalto a transporte público\n\nhttps://t.co/6Ff1iewafX https://t.co/eRfyw8RLZy"
## [4] "Hombres armados incendian transporte público en #Acapulco https://t.co/WPPQqGckq9 https://t.co/LRzjM0mvPO"
## [5] "Hombres armados incendian transporte público en #Acapulco https://t.co/FbmZNWJPKN https://t.co/VSNemKS0S5"
## [6] "Según la Veeduría Distrital, la capital necesita con urgencia reducir las emisiones de CO2, producidos principalmente por el transporte público y los vehículos de carga pesada. https://t.co/oSJYsyMRu5"
## [7] "El #CMin aprueba un RD para mejorar la #accesibilidad al transporte de las personas con #discapacidad.\n\n♿️Acceso de las sillas de ruedas eléctricas y escúteres a los medios de transporte.\n🐕Afectados por epilepsia y diabetes podrán viajar en transporte público con su perro. https://t.co/MW5BTsZzgB"
## [8] "Ósea el asunto no es solo así por así, hay que tener en cuenta otras medidas como el Transporte, la eficiencia del transporte público etc. \nDejen de andar pidiendo desniveles como dulces porque aparentemente ni en Peru esa es la solución. \nCierro hilo."
## [9] "@cronicaglobal TODOS queremos un transporte Público sostenible, pero lo queremos eficiente...Esperas mas de 6 minutos en hora punta no es eficiencia..."
## [10] "Me caga cuando alguna persona se le queda viendo a mi cartera cuando la saco para pagar el transporte público. \nQue esperan ver? Un chingo de billetes? …......\nNo ven que estoy igual de jodido que ellos y por eso voy en la combi también."Este texto es necesario limpiarlo para que sea más fácil de utilizar.
10.1.9 Armado del corpus con tm
- Primero creo un objeto de tipo Corpus. Utilizamos algo distinto a los conocidos vectores of dataframes porque es un objeto optimizado para trabajar con texto. Esto nos permite que los procesos sean mucho más eficientes, y por lo tanto trabajar con grandes corpus de manera rápida
10.1.10 Limpieza del Corpus
- Con la función
tm_mappodemos iterar sobre el corpus aplicando una transformación sobre cada documento (se acuerdan de la libreríaPURRR?)
En este caso, para la limpieza utilizaremos las siguientes transformaciones.
- Pasar todo a minúscula (cómo la función que usamos no es de la librería
tmtenemos que usar tambiéncontent_transformer) - Sacar la puntuación
- Sacar los números
- Sacar las stopwords
myCorpus = tm_map(myCorpus, content_transformer(tolower))
myCorpus = tm_map(myCorpus, removePunctuation)
myCorpus = tm_map(myCorpus, removeNumbers)
myCorpus = tm_map(myCorpus, removeWords, stopwords(kind = "es"))También deberíamos sacar las palabras que utilizamos para descargar la información.
# metrovias OR bondi OR Subte OR autopista OR transporte público
myCorpus = tm_map(myCorpus, removeWords, c('metrovias', 'bondi','subte','autopista','transporte', 'público' ))## <<SimpleCorpus>>
## Metadata: corpus specific: 1, document level (indexed): 0
## Content: documents: 10
##
## [1] ▶ dos sujetos robaron usuarios vehículo httpstcocfsjkrwf httpstcougyncyluz
## [2] detienen dos menores asalto httpstcorvnkplvv httpstcomovowluie
## [3] detienen dos menores asalto \n\nhttpstcoffiewafx httpstcoerfywrlzy
## [4] hombres armados incendian acapulco httpstcowppqqgckq httpstcolrzjmmvpo
## [5] hombres armados incendian acapulco httpstcofbmznwjpkn httpstcovsnemkss
## [6] según veeduría distrital capital necesita urgencia reducir emisiones co producidos principalmente vehículos carga pesada httpstcoosjysymru
## [7] cmin aprueba rd mejorar accesibilidad personas discapacidad\n\n♿️acceso sillas ruedas eléctricas escúteres medios \n🐕afectados epilepsia diabetes podrán viajar perro httpstcomwbtszzgb
## [8] ósea asunto solo así así tener cuenta medidas eficiencia etc \ndejen andar pidiendo desniveles dulces aparentemente peru solución \ncierro hilo
## [9] cronicaglobal queremos sostenible queremos eficienteesperas mas minutos hora punta eficiencia
## [10] caga alguna persona queda viendo cartera saco pagar \n esperan ver chingo billetes …\n ven igual jodido voy combipodemos ver que nos quedaron unos que son la forma de representar el “enter”. Lo mejor sería eliminarlos.
También queremos sacar los links. Para eso vamos a usar expresiones regulares para definir el patron que tiene un link, y luego crearemos una función que los elimine.
10.1.10.1 Expresiones regulares
Para que sea más sencilla la construcción de la expresión regular, usamos la librería RVerbalExpressions
# devtools::install_github("VerbalExpressions/RVerbalExpressions")
library(RVerbalExpressions)
expresion <- rx() %>%
rx_find('http') %>%
rx_maybe('s') %>%
# rx_maybe('://') %>% #como ya lo pasamos por los otros filtros, ya no hay puntuacion
rx_anything_but(value = ' ')
expresion## [1] "(http)(s)?([^ ]*)"Probamos la expresion con un ejemplo
txt <- "detienen dos menores asalto transporte público\n\nhttpstcoffiewafx httpstcoerfywrlzy"
str_remove_all(txt, pattern = expresion)## [1] "detienen dos menores asalto transporte público\n\n "Lo pasamos por el corpus
myCorpus = tm_map(myCorpus, content_transformer(function(x) str_remove_all(x, pattern = expresion)))
myCorpus = tm_map(myCorpus, content_transformer(function(x) str_remove_all(x, pattern = '\n')))## <<SimpleCorpus>>
## Metadata: corpus specific: 1, document level (indexed): 0
## Content: documents: 10
##
## [1] ▶ dos sujetos robaron usuarios vehículo
## [2] detienen dos menores asalto
## [3] detienen dos menores asalto
## [4] hombres armados incendian acapulco
## [5] hombres armados incendian acapulco
## [6] según veeduría distrital capital necesita urgencia reducir emisiones co producidos principalmente vehículos carga pesada
## [7] cmin aprueba rd mejorar accesibilidad personas discapacidad♿️acceso sillas ruedas eléctricas escúteres medios 🐕afectados epilepsia diabetes podrán viajar perro
## [8] ósea asunto solo así así tener cuenta medidas eficiencia etc dejen andar pidiendo desniveles dulces aparentemente peru solución cierro hilo
## [9] cronicaglobal queremos sostenible queremos eficienteesperas mas minutos hora punta eficiencia
## [10] caga alguna persona queda viendo cartera saco pagar esperan ver chingo billetes … ven igual jodido voy combiCreamos una matriz de Término-documento
## <<DocumentTermMatrix (documents: 17697, terms: 43484)>>
## Non-/sparse entries: 227647/769308701
## Sparsity : 100%
## Maximal term length: 137
## Weighting : term frequency (tf)
## Sample :
## Terms
## Docs así ciudad gente metro movilidad publico ser servicio sistema uso
## 10446 0 1 0 0 0 1 0 0 0 0
## 11678 0 0 0 0 0 0 0 0 0 0
## 11689 0 0 0 0 0 0 0 0 0 0
## 12916 0 0 0 0 0 0 0 0 0 0
## 13169 0 0 1 0 0 0 0 0 0 0
## 13736 0 0 0 1 0 0 0 0 0 0
## 16210 0 0 0 0 0 1 0 0 0 0
## 2359 0 0 0 0 0 0 0 0 0 0
## 3539 0 0 0 0 0 0 0 0 0 0
## 5963 0 0 0 0 2 0 0 0 0 0palabras_frecuentes <- findMostFreqTerms(myDTM,n = 25, INDEX = rep(1,nDocs(myDTM)))[[1]]
palabras_frecuentes## publico gente ciudad metro servicio ser movilidad
## 1425 1081 1026 934 890 737 692
## así sistema uso hoy mejor día solo
## 583 572 572 560 557 553 533
## hacer personas mejorar menos hace usar bien
## 532 512 498 495 491 485 461
## puede vez calidad tener
## 447 446 443 44110.1.11 Topic Modeling
necesito eliminar los documentos vacíos (que luego de la limpieza quedaron sin ningúna palabra)
## [1] 17697 43484## [1] 17677 43484lda_fit <- LDA(dtm, k = 10,method = "Gibbs", control = list(delta=0.6,seed = 1234))
lda_fit
saveRDS(lda_fit,'resultados/lda_fit.rds')## Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
## [1,] "mejorar" "movilidad" "servicio" "ciudad" "día"
## [2,] "hace" "uso" "ser" "pasaje" "cada"
## [3,] "puede" "coche" "madrid" "bogotá" "hoy"
## [4,] "medio" "vehículos" "mejor" "sabe" "vez"
## [5,] "centro" "semana" "personas" "claudialopez" "hora"
## [6,] "años" "bici" "debe" "parís" "trabajo"
## [7,] "tránsito" "bicicleta" "buen" "tan" "menos"
## [8,] "algún" "ciudad" "vas" "huelga" "bien"
## [9,] "utilizar" "privado" "debería" "reforma" "horas"
## [10,] "evitar" "millones" "defensa" "precio" "voy"
## Topic 6 Topic 7 Topic 8 Topic 9 Topic 10
## [1,] "gente" "pasajeros" "publico" "sistema" "usar"
## [2,] "metro" "vía" "seguridad" "calidad" "solo"
## [3,] "enciudad" "unidades" "casa" "hacer" "mejor"
## [4,] "luisdejesus" "usuarios" "auto" "problema" "van"
## [5,] "viajar" "aumento" "atención" "gobierno" "mal"
## [6,] "ahora" "tarifa" "llegar" "tener" "así"
## [7,] "caminar" "sep" "espacio" "parte" "buses"
## [8,] "país" "unidad" "luego" "claudiashein" "vida"
## [9,] "crisis" "falta" "seguro" "cdmx" "menos"
## [10,] "caracas" "dos" "cuenta" "autos" "bien"topicmodels_json_ldavis <- function(fitted, dtm){
svd_tsne <- function(x) tsne(svd(x)$u)
# Find required quantities
phi <- as.matrix(posterior(fitted)$terms)
theta <- as.matrix(posterior(fitted)$topics)
vocab <- colnames(phi)
term_freq <- slam::col_sums(dtm)
# Convert to json
json_lda <- LDAvis::createJSON(phi = phi, theta = theta,
vocab = vocab,
mds.method = svd_tsne,
plot.opts = list(xlab="tsne", ylab=""),
doc.length = as.vector(table(dtm$i)),
term.frequency = term_freq)
return(json_lda)
}